


Hey, Luca here, welcome to a weekly edition of the💡 Monday Ideas 💡 from Refactoring! To access all our articles, library, and community, subscribe to the full version:
Resources: 🏛️ Library • 💬 Community • 🎙️ Podcast • ❓ About
Brought to you by:

Today’s sponsor is Augment Code — the only AI engineering platform built for real engineering teams!
1) ❤️🩹 The Four Struggles
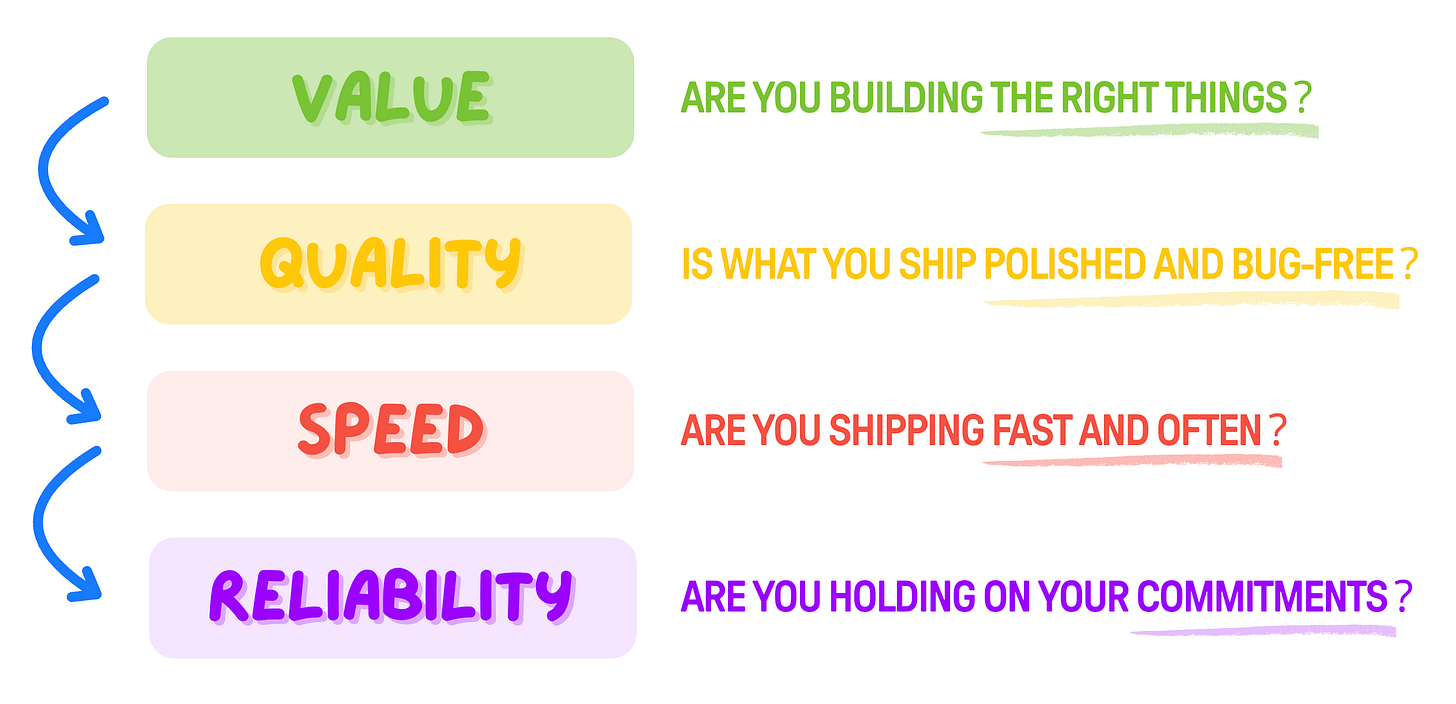
When you look at a team that is struggling, and try to figure out what the problem is, there are four big candidates:
🏆 Value — what gets shipped isn’t valuable to customers / business. You build the wrong thing.
🥇 Quality — what gets shipped is not polished and/or is constantly bugged.
🥈 Speed — the team is (or is perceived as) slow.
🥉 Reliability — the team doesn’t hold on to its commitments.
Your mileage may vary, but as a rule of thumb, these matter exactly in this order.
In my experience, working on the right things is by far the most important factor. Many teams have misguided conversations about speed when they really mean: “we’re not confident what we ship is good, so let’s ship more things faster“. There is some merit to this, but it’s also true that teams that ship valuable, high-quality work rarely get questioned about speed.
Working on the right things is a function of good feedback loops with customers, and feedback loops are what makes speed genuinely useful. Otherwise, you may be running fast, but in circles, without really going anywhere.
Finally, reliability — meant as meeting deadlines, making good estimates, etc — is just cherry on top. When trust is created through the other factors, you discover most deadlines are fictional and estimates are not that useful. In most cases, these are control devices meant to make up for low-trust environments, and most often fail at that. Under good conditions, you can relax a lot of the process and just let people work.
I wrote a full piece on how to help a struggling team, you can find it below 👇

2) 🎽 Durable teams vs task forces
This summer I spoke with Shopify's Director of Product to explore how they execute their giant bi-annual editions.
One of the ideas that stuck the most with me was how they used both long-lived teams and task forces which are assembled just in time:
🌳 Durable Teams — own complex areas where deep domain knowledge is critical. Permanent teams allow to build expertise over many years, which ensures the most critical parts of the platform are stable and stewarded by those who know them best.
🪖 Task Forces — are assembled to tackle new, experimental, or horizontal initiatives. For example, a task force might be spun up to build the first version of an AI feature that cuts across multiple product areas. This allows to bring together a diverse mix of experts to move quickly on a focused goal, without being burdened by the legacy or biases of any single product area.
The goal of this model is, in a way, to have your cake and eat it too. Durable teams provide the rock-solid foundation, while task forces provide the agility and firepower to make bold bets and drive innovation.
Ultimately, this should help strike a balance between stability and innovation. So, if you are primarily working in one of the two modes, you can ask yourself these questions:
If you mostly do task forces / feature teams: are you creating valuable product expertise for the long term?
If you mostly do long-lived teams: are you making enough bold bets, as opposed to incremental improvements?
You can find the full exploration here:
3) 🔍 Testing in production
In July I interviewed Maude Lemaire, Principal Engineer at Slack and Github and author of the awesome book Refactoring at Scale.
Maude has worked on some of the most daunting migration projects ever, like moving Github massive infrastructure from on-prem to cloud-native, and she strongly advocates for testing in production.
“I love testing things in production. And like, I know that this is probably a spicy take... There’s so much value!”
Even if this is often considered controversial, she says the value is obvious:
💰 Cost efficiency — building true production-like staging environments gets expensive fast.
🎯 Real conditions — you’ll never perfectly replicate production traffic patterns, cache states, and edge cases.
⚖️ Risk vs reward — especially for startups, the risk is lower and the learning is higher.
🔄 Faster feedback — real user behavior provides invaluable insights.
Even at Slack’s scale, they relied heavily on synthetic traffic in production rather than trying to perfectly mirror their systems. The key is having proper monitoring, feature flags, and the ability to quickly roll back when issues arise.
This approach becomes even more essential as systems grow larger and more complex — at some point, true staging environments become practically impossible to maintain.
Here is the full interview with Maude:
You can also find it on 🎧 Spotify and 📬 Substack
And that’s it for today! If you are finding this newsletter valuable, consider doing any of these:
1) 🔒 Subscribe to the full version — if you aren’t already, consider becoming a paid subscriber. 1700+ engineers and managers have joined already! Learn more about the benefits of the paid plan here.
2) 📣 Advertise with us — we are always looking for great products that we can recommend to our readers. If you are interested in reaching an audience of tech executives, decision-makers, and engineers, you may want to advertise with us 👇
If you have any comments or feedback, just respond to this email!
I wish you a great week! ☀️
Luca