

How to Orchestrate AI Workflows
Navigating tradeoffs between pure AI and deterministic software

Hey, Luca here! Welcome to a weekly essay from Refactoring.
Every week I write an article about how to ship fast and make good software, and interview a world-class tech leader. I also build and maintain Tolaria in the open, publishing my workflows and learnings here.
Refactoring is read every week by 170,000+ engineers and managers from all over the world 🙏🙇♂️
Hey there! Last week’s article about my workflows for Tolaria went incredibly well, and I got a ton of replies and questions via email.
One of the most recurring ones was: what’s next? How would you improve this?
Happy to answer. I have been building AI workflows for a while now, and, for the most part, I have done so in “100% AI mode” — that is, I tell an agent to do something recurringly, in natural language, and they do it.
These workflows are fast to ship and *mostly* work, but also have pretty obvious drawbacks, that I would love to discuss today.
I believe this is relevant because these days we are inundated by stories like: “n8n is dead!”, “it’s all agents calling agents!”, and so on, while reality is more complicated.
I also bounced a lot of ideas off with the team at Kestra, who runs an awesome open source platform for orchestrating workflows. Their help came at the perfect time, and we basically wrote this piece together.
So here is the agenda:
🧹 Cleaning up releases — starting from a real-world example.
⚖️ AI vs Orchestration — mapping pros and cons of how to run workflows.
🏗️ Agents as scaffolding — a useful mental model about going AI first, but gradually replacing it with code.
🗺️ Workflow engineering journey — a maturity model for developing your workflows.
Let’s dive in!
Disclaimer: I am thankful to Kestra for partnering on this piece and providing ideas and insights about the orchestration industry. I am a fan of what they build and you should check it out:
However, as always I will only write my unbiased opinion on the practices and tools covered, Kestra included.
🧹 Cleaning up releases
To stay grounded and make you understand what I mean when I say workflows, let’s take a practical example. Whenever I create a new stable release for Tolaria, I have an automation to take care of the release’s aftermath.
This includes fetching all the bug fixes and feature requests that were shipped in the release, and update/close them in the respective channels, notifying the relevant users.
This is not rocket science by any means, but it involves a number of steps:
Fetch Github commits shipped with release
Match commits to the associated tasks on Todoist
For each task, retrieve the original entry either on Github Issues, or the Canny product board
For each Github issue, leave a comment saying this is fixed in the latest release, and close the issue
For each Canny item, leave a comment explaining how this was implemented in the latest release, and close the item
Finally, create short descriptive release notes to be attached to the release page.
The first version of this was entirely run by AI. No scripts — just a few high-level skills about how to access Github Issues, Canny, and Todoist — and natural language instructions about what needed to happen.
This mostly works. Sure, it is slow and expensive, but that’s forgivable given that I need to run it at most once per day. The problems come when it doesn’t work for any reason.
Say Github issues are not available at that specific time (ofc fantasy example given Github’s immaculate availability lately), or the run times out, or your favorite AI provider rate limits you in that very moment.
At that point the workflow fails, and it typically does so in the worst possible way: 1) silently, 2) leaving things in a dirty state, and 3) without any retry or recovery.
Of course you may build all of these into the procedure somehow, but if you find yourself manually plumbing standard ideas about how we have been running workflows since... forever, you should probably stop and ask yourself if there is a better way.
So let’s take a step back and think through this from first principles.
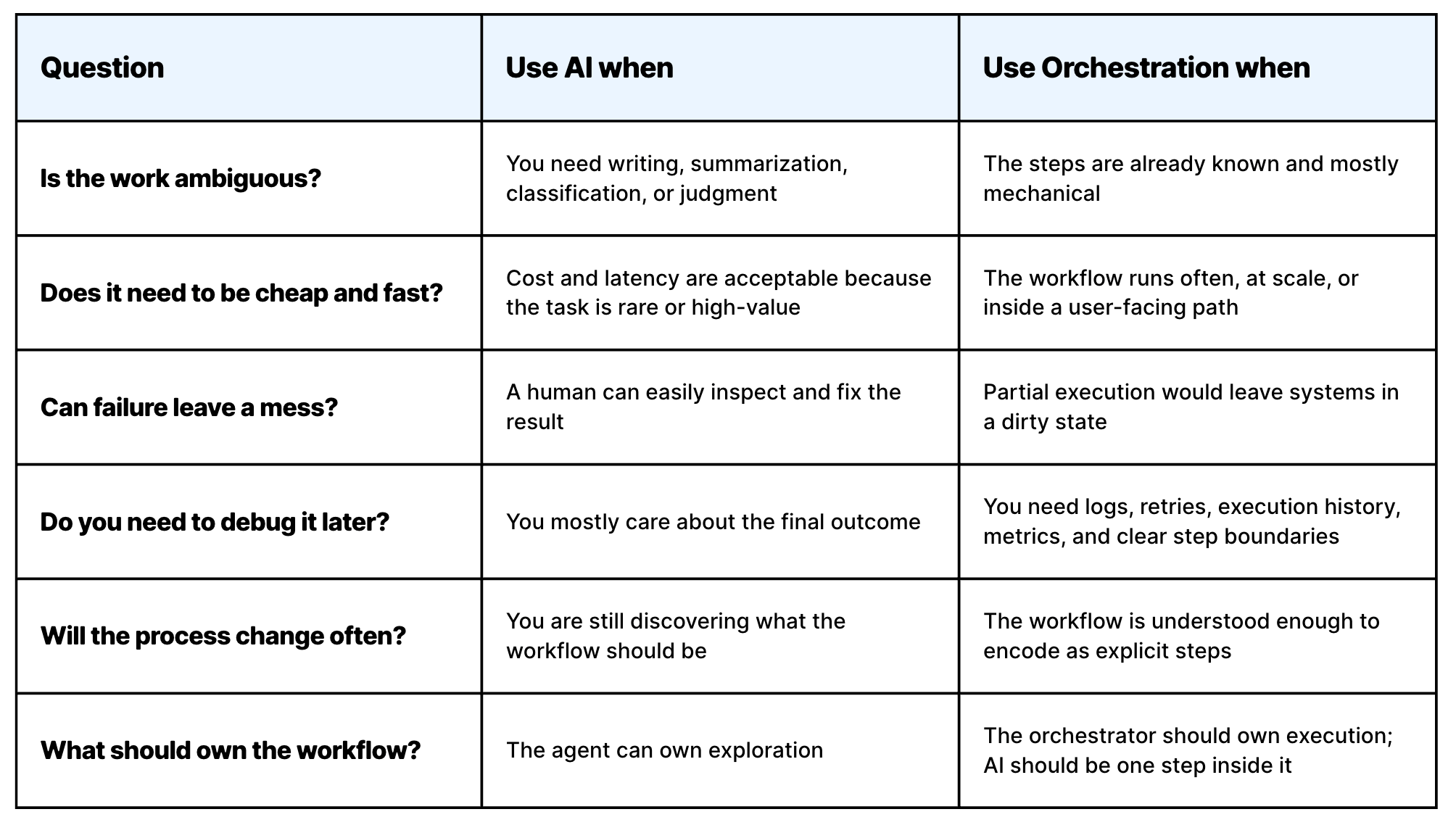
⚖️ Pure AI vs Orchestration
The tradeoffs between pure AI workflows (e.g. cron jobs on OpenClaw) and orchestration platforms a-la Kestra, resemble a lot those between AI and deterministic software.
AI is incredibly smart, but also incredibly expensive and slow. A lot of work just doesn’t need those smarts. Routing, retries, conditionals, scheduling — there is just a lot of plumbing that can be done in a purely deterministic way, saving time & money.
Also, traditional orchestration doesn’t only win on time and money: it is often a better choice full stop when you account for:
Observability — you can’t debug pure LLM reasoning, as you can instead with workflow steps that are explicit and isolated. Also you get execution history, stats, and much more.
Reliability — scheduling, resiliency, recovery from failures. This should be all built-in.
Scalability — this is probably not a factor on its own, but more the result of all of the above combined. Being able to scale requires reliability, observability, low latency, and so on.
So where do we go from here?
🏗️ Agents as scaffolding
A few weeks ago, Will Larson published an awesome piece about using agents as scaffolding for recurring tasks, which means: a useful first pass to discover what the workflow should be.
Then, once the pattern is known, you should extract and harden as much as you can into deterministic code. So agentic steps are largely used as prototyping tools, not permanent infrastructure.
This doesn’t mean eventually replacing all of the AI, but rather only using AI for the right things. With some degree of simplification:
Orchestration wins at all-things-infra — observability, reliability, human-in-the-loop approvals, structured output validation, and so on.
AI wins at the messy stuff — classification, summarization, judgment calls, and all the things you can’t write code for.
I love this take, and I think we can expand it into an actual maturity journey 👇
🗺️ Workflow engineering journey
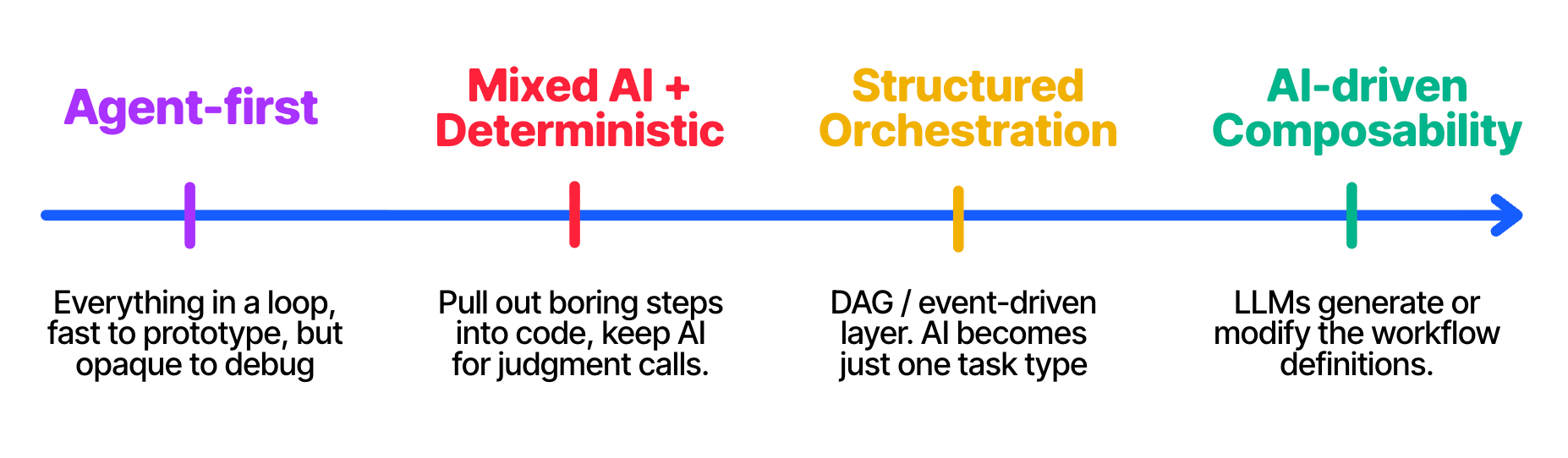
Based on this, a natural progression may look like this:
Agent-first — everything in a loop, fast to prototype, but opaque to debug.
Isolate the deterministic parts — pull out the boring steps (fetch, validate, store, etc) into explicit code. Keep AI for judgment calls.
Structured orchestration — proper DAG / event-driven layer with retries, lineage, observability. AI becomes one task type among many.
AI-driven composability — LLMs generate or modify the workflow definitions themselves. The orchestration layer is stable enough to be a target for code generation.
I am particularly bullish about #4 because, when you think about it, it is a way to get the best of both worlds: you prompt the AI in natural language as you would for normal agentic workflows, but the AI actually turns that into structured, semi-deterministic work.
A quick plug to Kestra on this, which I am a big fan of. Because if you agree with these steps, a natural question becomes: what should an orchestration platform look like to enable AI to operate it? Kestra checks a lot of my boxes:
Code-first — the AI should be able to write workflows in a declarative fashion, with code, because that’s what it’s best at (as opposed to e.g. GUIs).
API/CLI first — trigger executions and manage workflows through API
Open source — these days, considering the speed tech is moving at, I put a lot of value on the tools I use being open source, so we can evolve them faster as a community, in the open, and there is less lock-in.
And that’s it for today! I wish you a great week
Sincerely 👋
Luca
The "agents as scaffolding" framing is the right inversion. Most teams treat AI runs as the destination; treating them as bootstrapping for deterministic code makes the maturity model actually testable. The hidden cost in 100-percent-AI workflows is debugging without idempotency, where a step silently re-runs with different state and replays stop reproducing. That's the wall most agent-orchestration writeups skip past.