

The Era of the Software Factory 🏭
A reflection based on the latest State of Software Delivery report

A few weeks ago, I had Rob Zuber, CTO of CircleCI, on the Refactoring podcast.
We discussed how AI is changing software delivery, and the conversation continued well after we stopped recording.
A few weeks later, Rob shared an early copy of CircleCI’s State of Software Delivery 2026 report—which comes out today—and the data connected a lot of the dots from our conversations. So we decided to write this piece together: my take on the findings, with Rob’s perspective from the inside.
The report is based on 28+ million CI workflows across thousands of teams worldwide, and reveals something we have long suspected: the performance gap between top and average teams is widening. And it’s widening fast.
Elite teams (99th percentile) are reaching delivery speeds that would have been unimaginable two years ago, while the median team hasn’t moved much at all.
One story from my earlier interview with Rob captures this well. A team at CircleCI was debating whether to run user research for a new feature—the usual approach. Rob pushed back: just build a prototype overnight and test it with real users.
Even if the code was, worst case, 100% throwaway, the learning would be more accurate, and the cost would be just ~$100 in compute and a few hours of an engineer. The alternative would have been weeks for the research, more people involved, and possibly more shallow insights.
For someone like me, who has been involved in startups and lean teams for his whole career, it’s counterintuitive to think code-first. Much of what we know about building products is based on the implicit assumption that writing code is the most expensive part, by far.
So when such cost drops, the initial outcome is that engineers get faster. But when it keeps dropping, like in the last year, we get to a point where a lot of hypotheses don’t hold anymore, and we need to rethink the process as a whole: how we make decisions, how we structure teams, how we think about quality, and so on.
You stop optimizing individual developers, and start designing a new production system. Rob and I started calling this the software factory, and it became the lens through which the rest of this piece came together.
Here is what we’ll cover:
🏭 From craftsman to factory — why this is bigger than “AI makes coding faster”
📊 The widening gap — data from the 2026 State of Software Delivery
🎛️ Control systems thinking — a mental model for running your factory
⚡ What elite teams do differently — practices, not tools
🛠️ How to start — without rebuilding everything
Let’s dive in!

I am grateful to Rob and the CircleCI team for partnering on this piece and giving me preview access to their report. You can check it out below.
Disclaimer: even though CircleCI is a partner for this piece, I will only provide my unbiased opinion on all practices and tools we cover, CircleCI included
🏭 From Craftsman to Factory
Let’s lead with an interesting bit from the State of Software Delivery. Actually, three bits:
Activity on feature branches (where most coding happens) is up 59% YoY — the largest increase ever observed.
Activity on the main branch, though, which is closely correlated with production deployments, is down by 7%.
Build success rates are down to 70.8%, the lowest in five years.
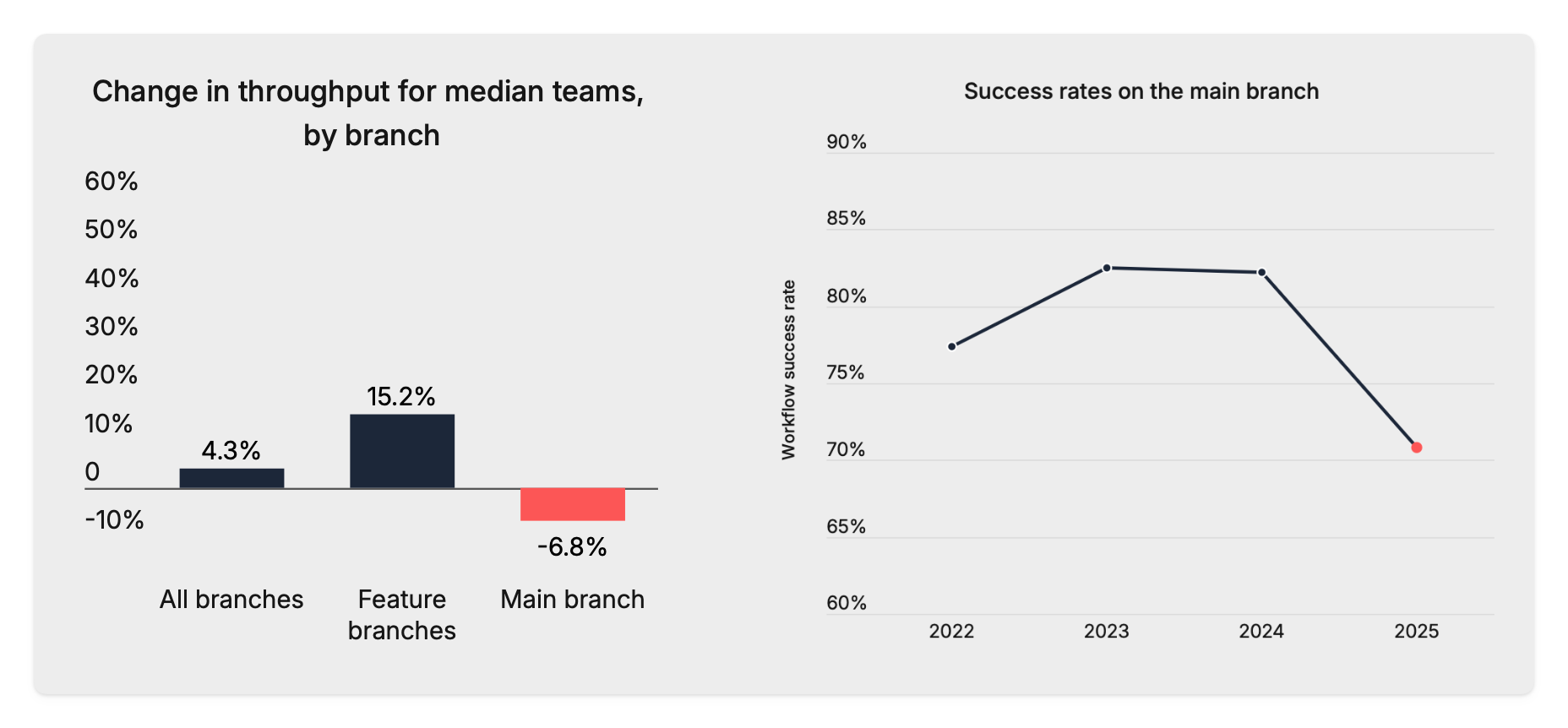
The way I see it is that engineers by now are comfortable with AI-assisted coding, and, as a result, teams are generally writing more code than ever. But it also feels that, when it comes to shipping, this confidence drops. Code fails more often, which makes engineers less eager to merge and deploy.
So while AI makes the generation of code faster, everything that comes after (or before) that — testing, reviewing, integrating, deploying — largely stays the same (or gets worse!), unless you do something about it.
I’ll also throw in my own experience into the mix. For the last two months, I have been running a small-group coaching program for CTOs where, among other things, I help them identify the bottleneck in their dev process — the step that limits the throughput of the overall system.
In theory, that bottleneck can be anywhere. In practice, it’s never coding.
For some, it’s manual QA. For others, it’s creating good requirements. For many, it’s code reviews. For one of them, it’s collecting good feedback from customers, so they can act on it.
As coding gets cheaper and faster, it’s changing the cost structure of the whole process, and bottlenecks now live in the parts that AI hasn’t attacked yet. In other words, the whole system is up for discussion, and chances are it’s going to look way more like a factory than today’s craftman’s workshop.
Steve Yegge’s Gas Town is an obvious example that comes to mind. If you forgive the chaos, the waste of tokens, and the Mad Max theme, it looks directionally correct to me: a system of agents coding in parallel, orchestrated by higher-level agents that create and execute plans, and report back to their human overlords.
But as much as Gas Town can look at times like a 360° self-sustaining orchestration system, it’s still only focused on coding! Love this quote from Dan Lorenc:
Gastown is a preview of agent programming, but the future isn’t “code gets written faster.” The future is: change gets shipped faster. And those are not the same thing.
Teams are trapped because CI takes forever, tests are flaky or missing, review cycles are slow, merge conflicts pile up, confidence is low, production is fragile, and there are “oh god please don’t touch that” zones nobody wants to own.
If this plays out the way I think it will, software engineering turns into CI engineering.
Code is cheap. Green CI is priceless.
So how do we build what’s missing? Let’s go back to the data 👇
📊 The Widening Gap
We were saying: more code, more breakage, less delivery.
This problem, though, is not hitting everyone equally. In fact, possibly the most striking finding from the report is how differently teams are responding to the same shift. Let’s look at throughput first:
The top 5% of teams nearly doubled their output YoY.
The bottom half is flat, or slightly declining.
And even within the elite, the spread is staggering: this year’s most productive team delivered roughly 10x the throughput of 2024’s leader. At positions 5–15, it’s around 3x. At 20–30, about 2.5x.
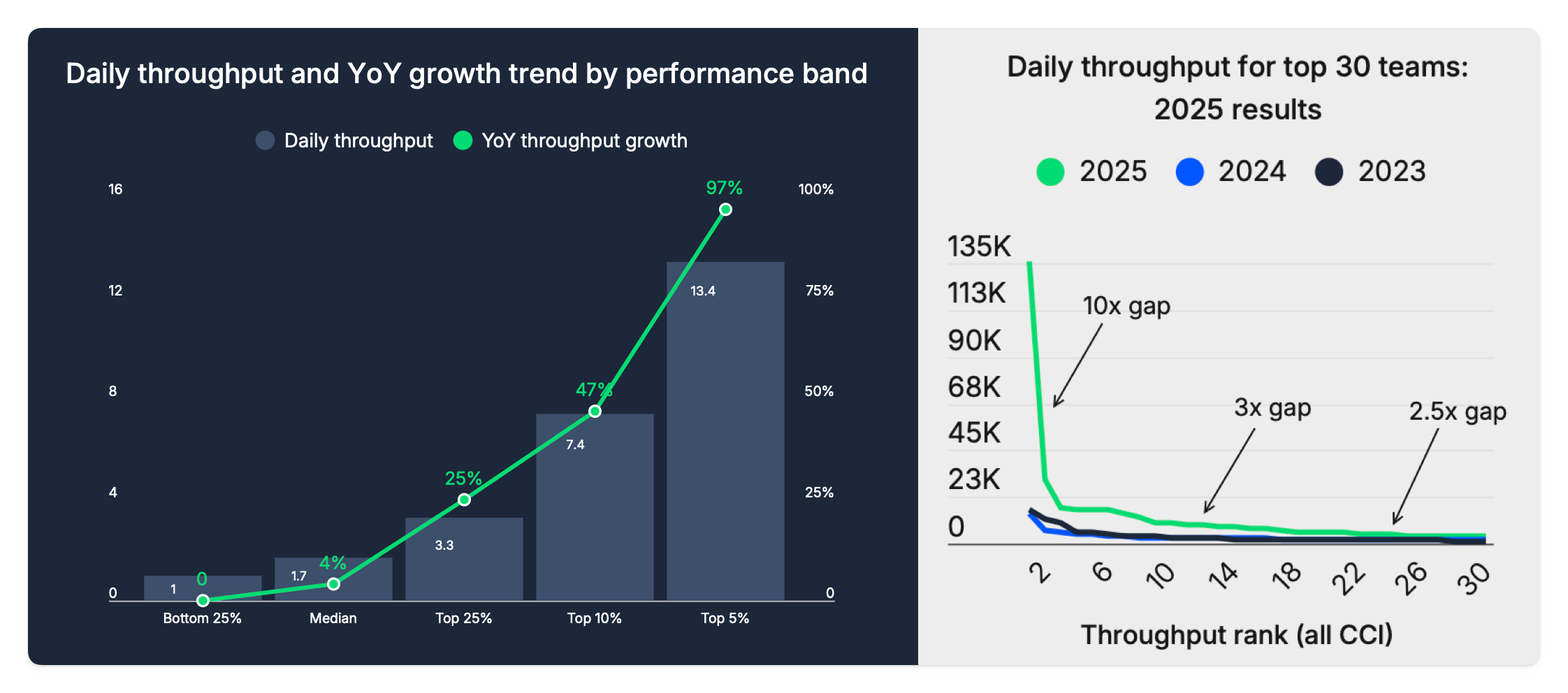
Pipeline speed tells a similar story:
Elite teams run at a median pipeline duration of <3 mins.
The average sits at 11 minutes.
Struggling teams are above 25 minutes.
That’s a ~10x gap between top and bottom, and we know the consequences: when your CI takes 25 minutes, you don’t run it as often, you batch more changes together, problems pile up, and the feedback loop slows to a crawl.
Recovery is perhaps the most telling metric. The median team takes about 72 minutes to get back to green after a failure — up 13% from last year. On feature branches, where AI is driving the most activity, recovery times jumped 25%. The average recovery time (as opposed to median) is 24 hours, which gives you a sense of how bad things get for the teams at the tail end.
Now, you might assume the gap is about resources — bigger companies, better tooling budgets, earlier access to AI. But that’s not what the data says. 81% of respondents report using AI in some form, so the tools are everywhere. What’s not everywhere is the ability to absorb what those tools produce.
I saved the best for last, so here is the data point I find the most interesting: teams that had CI pipelines under 15 minutes back in 2023 are 5x more likely to be in the 99th percentile today.
In other words, the teams that are thriving with AI are the ones that had good infrastructure before AI showed up. Fast feedback loops, reliable tests, clean deployment pipelines — all of that was built for humans, and it turns out it’s exactly what you need to make AI-generated code shippable.
How should you feel about this? In a way, this is both encouraging and frustrating. Encouraging, because there’s no secret: what’s good for humans is good for AI. Maybe also frustrating, because if you don’t have them, there’s no shortcut: AI amplifies whatever you already have, good or bad.
🎛️ Control Systems Thinking
So, if we are building a production system now, how should we think about it? Rob has an answer for this, and it comes from a somewhat unexpected place: control theory.
The field dates back to the early 1900s, and the core idea is simple. Think of a thermostat. You set a target temperature. A sensor measures the current temperature. If it’s too cold, the heater kicks in. If it’s too warm, it shuts off. The system continuously adjusts itself based on feedback.
That’s what a control system does, via four elements:
🎯 Setpoint — what you’re aiming for.
🌡️ Sensor — how you measure.
🔧 Actuator — what makes changes.
↩️ Feedback loop — that connects them.
Now replace the thermostat with a software team:
Your setpoint is the quality and speed of your delivery.
Your sensors are your tests, your CI pipeline, and your monitoring in production.
Your actuators are the agents and developers that write and ship code.
The feedback loop is everything that connects output back to input: did the build pass? Did the deploy break anything? Are users behaving as expected?
CI/CD has always been a control system; we just don’t call it like that. The teams that built fast pipelines, reliable test suites, and good observability have been essentially building sensors and feedback loops.
This framing matters today because if you just “unleash the agents” without good feedback mechanisms, you get what the data is already showing us: more code, more breakage, declining success rates.
So what the teams at the 99th percentile have is mostly faster and better feedback loops:
Their CI runs in under 3 minutes, not 25.
When something breaks, they know in minutes, not hours.
They can roll back quickly, which means the cost of a mistake is low, which means they can experiment more aggressively.
If we agree on that, the question becomes: if you are not one of those teams, where do you start?
🛠️ How to Start Building Your Factory
Just like I don’t like big rewrites, I don’t believe in redesigning everything at once. I believe in small steps that compound over time.
So let’s try to start with three simple things: speed up your feedback, share what works, and make experiments cheap:
1) Speed up your feedback
This is the single highest-leverage move for most teams. If your CI pipeline takes 20+ minutes, nothing else matters — every other improvement will be bottlenecked by how long it takes to know if something works.
A simple audit: how long does it take from “developer pushes code” to “you know if it’s good or broken”? If the answer is more than 10 minutes, start there. If you can’t roll back a bad deploy in under 5 minutes, start there. If your test suite is flaky enough that people ignore red builds, start there.
This isn’t glamorous work, and it has nothing to do with AI. But the data is clear: the teams that had this in place before the AI wave are the ones riding it now. It’s the foundation your factory needs before anything else.
2) Share AI practices as a team
One data point from the report stuck with me: 30% of developers say they have little to no trust in AI-generated code. They use it because everyone does, but they don’t trust what it produces.
30% is a lot.
I believe the way to fix this is not to wait for a better model, but to graduate AI adoption from an individual sport to a team one. Turn AI Engineering into Compound Engineering.
This doesn’t require a big investment. I love Will Larson’s series of articles where he displays how his team is navigating this at Imprint, and it’s all about the basics. Here are a few examples:
Create shared docs that accumulate learnings over time.
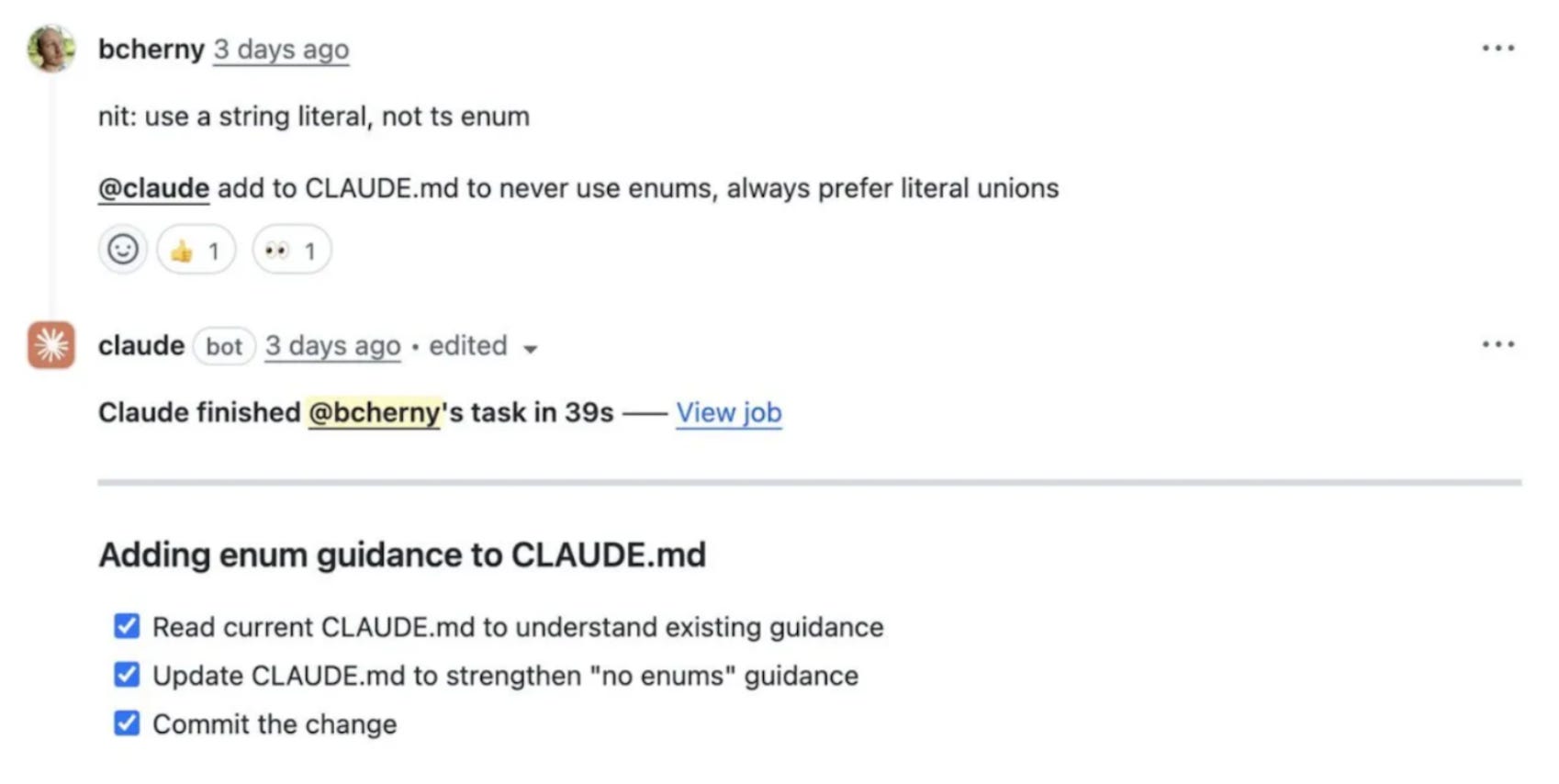
Turn agents instructions (e.g. CLAUDE.md) into a shared artifact (version controlled!) across the team.
Create easy ways to give feedback to the AI so that it can improve its own instructions (see screenshot from the Claude Code team 👇)
Create spaces in which people can show how they use AI, what they learned, and something cool they did. It’s as simple as a 30-mins weekly slot.
If you start doing this, the compounding effect is real: better practices lead to better results, which lead to more trust, which leads to more experimentation, which leads to better practices again.
3) Make experiments cheap
Finally, try to make all of this easy. Create opportunities to try frontier workflows in a way that feels low-stakes:
Run a hackathon where humans can’t write any code manually.
Start a project that would be impossible to deliver had humans written the code. Like Craft did.
Default-assign long-tail bugs to the AI and let it draft PRs.
Don’t treat AI adoption as a big decision, like: evaluate for three months, run a pilot, write a report, pick a winner. Treat it as continuous experimentation: try something this week, measure if it helped, keep it or kill it by Monday.
The cost of trying things has never been lower. The cost of not trying things has never been higher.
📌 Bottom line
And that’s it for today! If there’s one thing we hope you take away from this piece, it’s that the shift we’re living through isn’t about AI writing code faster. It’s about the entire system of building software being redesigned. And it’s being redesigned, in real time, by the teams that understood this first, and way before AI.
Here are the main takeaways:
🏭 The bottleneck is no longer coding — AI made code generation dramatically faster, but testing, reviewing, integrating, and deploying largely stayed the same. The teams pulling ahead are those redesigning the whole system, not just the coding step.
📊 The gap between top and average teams is stretching fast — elite teams nearly doubled their throughput YoY while the median barely moved. The difference isn’t access to AI tools (81% use them), it’s the infrastructure to absorb what those tools produce.
🎛️ Think of your delivery process as a control system — with setpoints, sensors, actuators, and feedback loops. The teams at the 99th percentile do ship faster, but also know faster whether something works, which lets them experiment more aggressively.
🔧 Good infrastructure before AI = good results with AI — teams that had CI pipelines under 15 minutes in 2023 are 5x more likely to be in the 99th percentile today. Fast feedback loops, reliable tests, and clean deployments were built for humans, and they are even more important for AI.
🤝 Graduate AI adoption from individual to team sport — shared docs, version-controlled agent instructions, feedback loops into AI tooling, and regular show-and-tell sessions create compounding returns that solo experimentation can’t match.
⚡ Make experiments cheap, not decisions big — don’t evaluate for three months. Try something this week, measure if it helped, keep it or kill it by Monday. The cost of trying has never been lower; the cost of not trying has never been higher.
See you next week!
Sincerely 👋
Luca
I want to thank Rob and the CircleCI team again for partnering on this. You can find out their yearly report below 👇
Really good framing of the problem.
What I've been seeing is that the "Individual to Team Sport" shift is the hardest part of this transition because it's a moving target problem.
I see more and more adoption asynchronicity, where "autocomplete-only" engineers work close to early adopters who have already moved from many MCP to self-evolving skills through claude code hooks.
The real difficulty I've been observing isn't just sharing docs or knowledge in general but it's that any rigid guideline or "best practice" becomes technical debt within months. We are no longer managing a static stack, but a co-evolution of human-agent workflows.
BTW: "What's good for humans is good for AI" this is absolutely true!
Great article.
Matches most of the things we are doing to accelerate AI Adoption, especially iterative progress, sharing obstacles and best practices etc.
I can't speed up the deployment and feedback, due to the unique nature of healthcare.
One best practice
I maintain and share a 4 quadrant list named 4O.
4O- Objectives, Outcomes, Observations and Obstacles.
That way we can avoid reinventing the wheel and accelerate from green field to brown filelds and complicated 'mine fields'.