


Once or twice a year we run a deep research survey in our newsletter to better understand trends in software development. We do this to collect broad, quantitative data, that complements the qualitative opinions we already get from podcast interviews, from our private community, and from my own 1:1 conversations.
Last year we explored AI adoption, while this year we decided to expand the scope and investigate what the whole product development process looks like for teams in 2026.
We chose this topic because I believe we need to look beyond coding. Coding is now cheaper and faster than ever, which, for many teams, is moving bottlenecks elsewhere.
But is that really the case? And, if so, where are the bottlenecks now?
This is what we tried to uncover this year. A few weeks ago I wrote that the best way to find friction in your dev process was to simply ask your engineers, by doing what I called a Listening Tour. This survey is like our own listening tour, done on 340 teams — and we are here to report on findings.

This research was made possible by our partnership with Atono.
Atono not only funded this work: they helped us with their expertise, insights from their customer base, and domain knowledge. I am a big fan of what they are building and how they think about product development. You should check it out!
So here is the agenda for today:
Demographics — a quick note on the data.
The Planning Problem — why 60% of teams discover missing work mid-cycle, every cycle.
AI in the Workflow — what teams are using AI for (and the one use case almost nobody has tried).
The Experimentation Gap — why some teams are compounding their AI advantage while others stay stuck.
The Way Forward — our conclusions, along with the three transitions we believe teams need to make.
Let’s dive in!
🗳️ Demographics
We surveyed 340 engineering professionals — a mix of ICs, tech leads, managers, and senior leaders — across companies ranging from 10-person startups to 1,000+ engineer orgs.
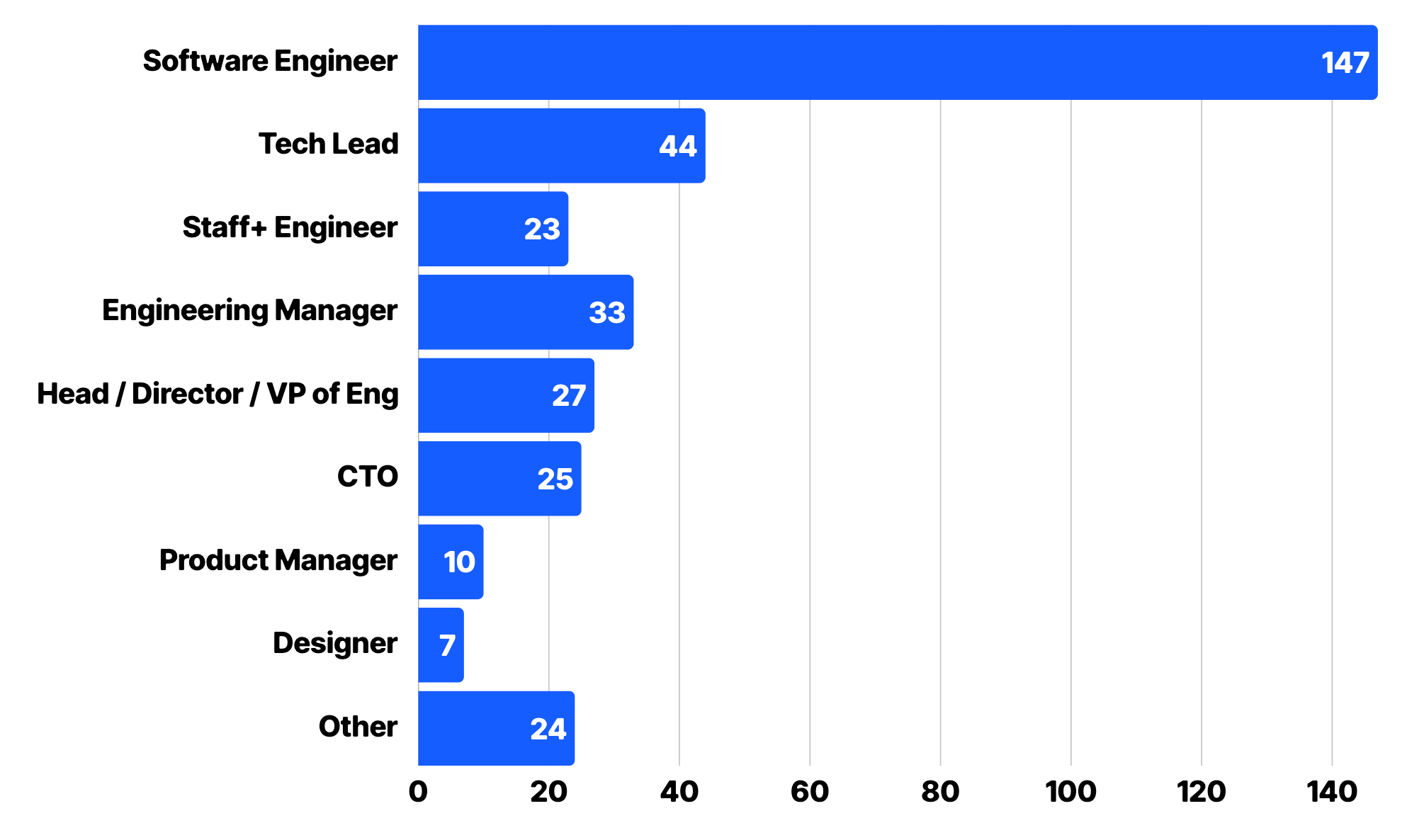
The survey was designed for depth over breadth: many questions were open-ended, and we reviewed every response manually. Each engineer took on average more than 15 mins to fill out the survey, so it was not quick, and it gives you an idea of the scale.
5️⃣ The Five Problems
To give you the bottom line up front, there are five key problems that tell the whole story:
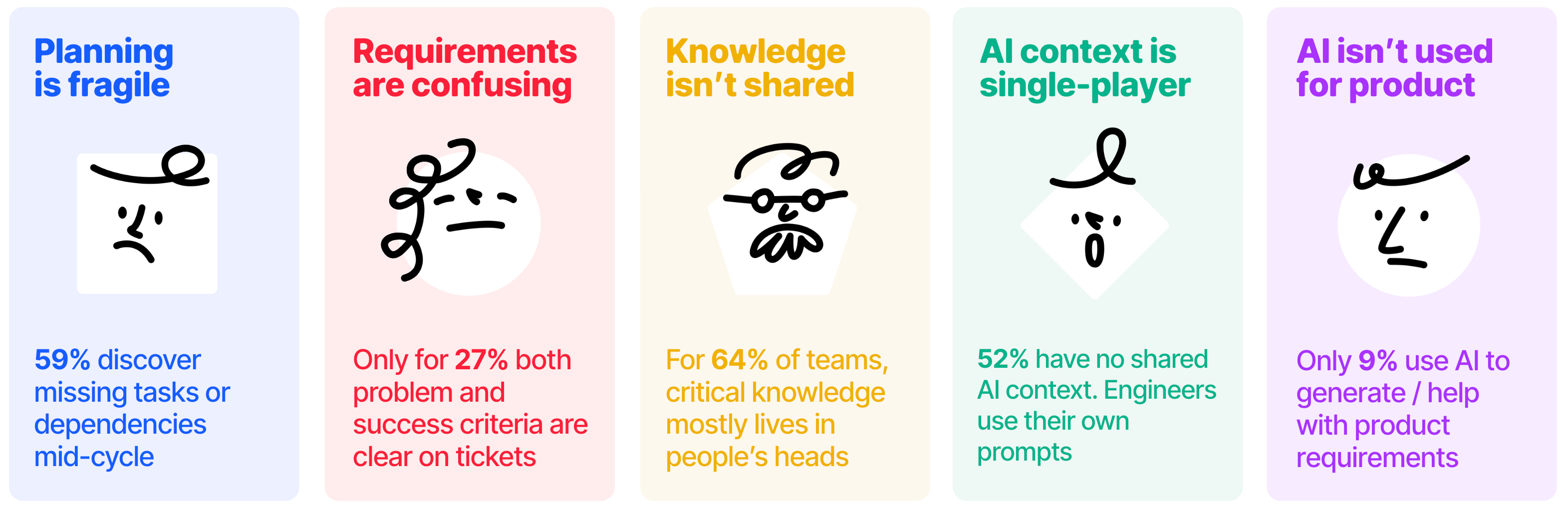
Product requirements are confusing — Only 27% of engineers say both the problem and the success criteria are clear when they read a ticket. The counterintuitive part is that engineers are more likely to understand why something is being built rather than what done looks like. In many cases, teams share intent but lack a shared definition of the product behavior they’re trying to produce. The definition of done becomes the bigger knowledge gap.
Planning is fragile, for companies of all sizes — 59% of engineering teams discover missing tasks, stories, or dependencies mid-cycle. This rate is flat from 10-person startups to organizations with 1,000+ engineers. Scale doesn’t fix it nor does it make it worse.
Knowledge doesn’t get shared — 64% of teams store critical knowledge primarily in people’s heads. 1 in 8 say institutional knowledge simply disappears when someone leaves. And the bigger the company, the worse it gets. At companies with 1,000+ engineers, that rises to 17%.
Shared AI context is still aspirational — half of the teams (52%) have simply no shared AI context. Each developer manages their own prompts, assumptions, and product definitions. In practice, this means the same AI tools often operate with different understandings of the product across the same team. Large companies are significantly worse at this than small startups (75% vs. 51%).
AI isn’t much used for product — Only 9% of teams use AI to generate or help with product requirements. This is the use case most directly tied to every planning problem in this report, and almost nobody is doing it. Teams use AI to write code while upstream problems that cause rework go untouched.
These numbers point to a few larger problems:
Most teams have adopted AI for coding, and little else.
Teams that adopted AI on top of a process that was already fragile—unclear specs, tribal knowledge, undocumented decisions—aren’t getting a lot out of it.
Teams getting the best results are the ones who had a solid product dev process before AI arrived. This is the same insight we found for coding a few weeks ago, which we can now extend to product.
So let’s dive into the details!
🗺️ The Planning Problem
It’s a common belief that engineering teams are plagued by rework and missing requirements. This is confirmed by data:
59% of teams discover missing tasks, stories, or dependencies mid-cycle.
60% of engineers say they need clarifying questions “often” or “almost always” before starting work. Only 8% say tickets give them everything they need.
When we asked what causes the most delays and rework, the top answer was ambiguous or missing acceptance criteria (50%), followed by edge cases discovered too late (40%).
We tend to assume requirements failures start with poor problem definition, but the data says the gap is usually at the other end, at the definition of done.
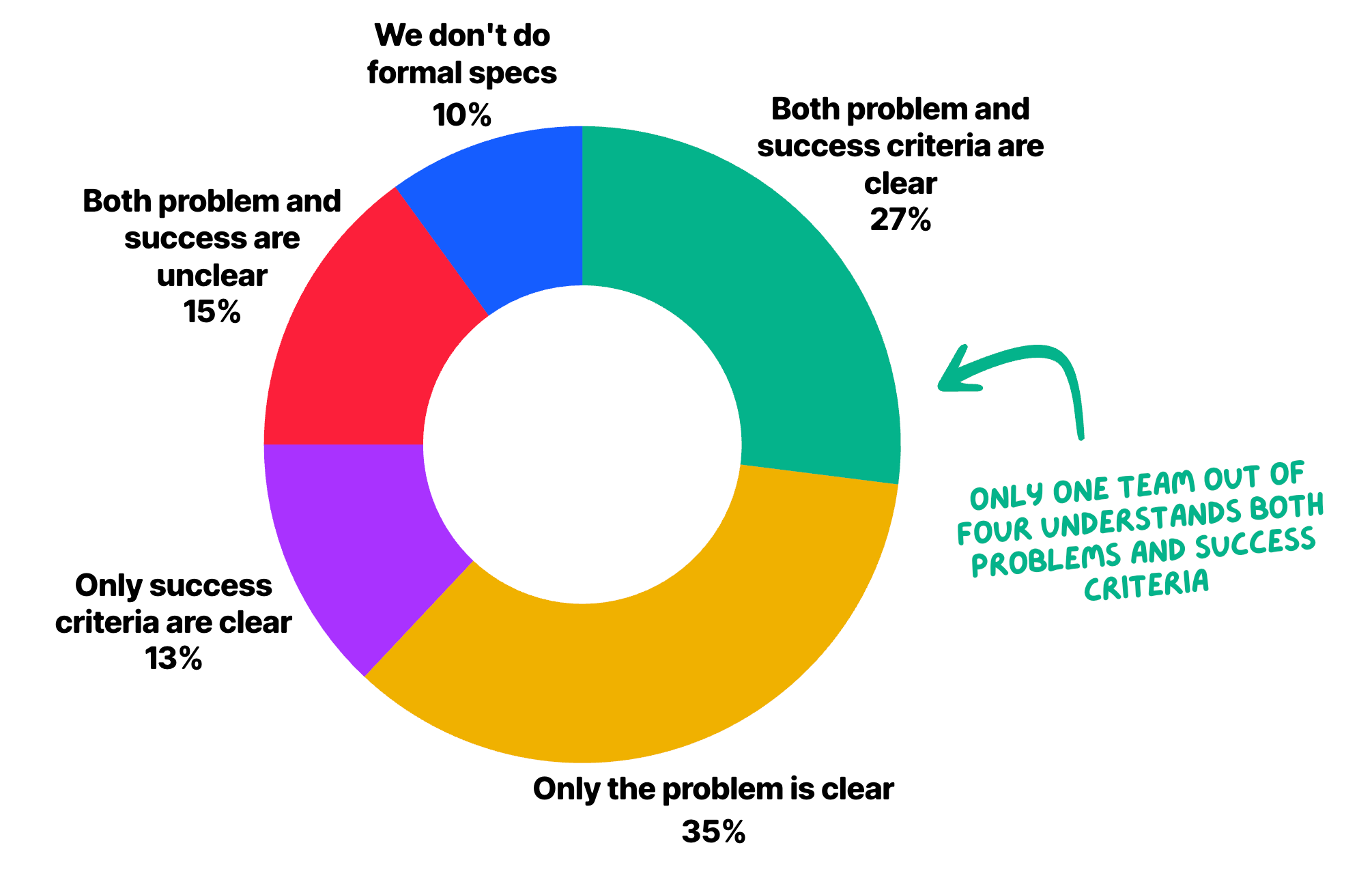
35% of engineers say they understand the problem but not the success criteria. Only 13% have the inverse problem. Engineers are more likely to understand why something is being built than what done looks like.
“Developer’s understanding of the story. They don’t ask enough questions during grooming which leads to incomplete ticket/story. At the same time POs provide very generic acceptance criteria making it difficult to reach the expectations.”
— Tech Lead
The mid-cycle discovery rate makes this more concrete: 59% say they find out mid-sprint that a task is bigger than expected, a dependency was missed, or a design doesn’t match the implementation. This rate barely changes with company size. 10-person startups and 1,000-engineer organizations report nearly identical numbers. The “planning problem” isn’t a size or scale problem.
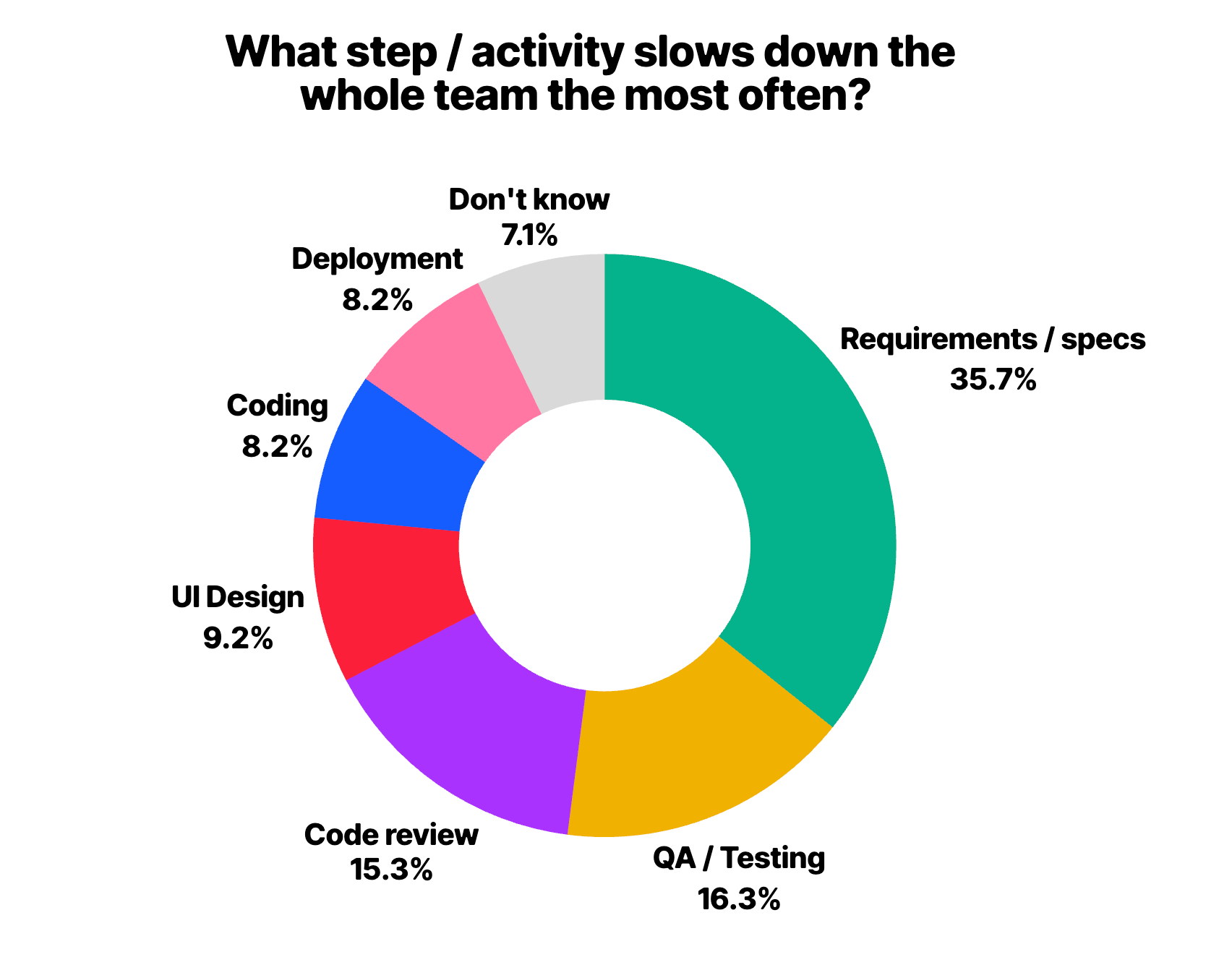
Requirements are also the #1 team bottleneck, by a wide margin. 35% of teams cite unclear or changing specs as the thing that most often slows the whole team down — twice the rate of the next item (QA and testing, at 16%).
“Most delays happen due to unclear or changing requirements that reveal hidden complexity once work begins.”
— Software Engineer
Part of why this persists is where product knowledge lives.
Two teams out of three store critical knowledge primarily in people’s heads. 57% say it’s scattered across Notion, Confluence, and Google Docs. 1 in 8 say it simply gets lost when someone leaves. Standard, agreed upon solutions for documenting technical decisions (like ADRs) are used by only 1 in 5 teams.
It goes without saying that when context lives only in people’s heads: it can’t be handed off cleanly, it can’t be referenced asynchronously, and it can’t be used by AI.
“Knowledge is scattered across Jira, docs, and code lives in multiple microservices working on different domains.”
— Engineering Manager
🪄 AI in the Workflow
It’s a common belief that AI has transformed how engineering teams work. The data seems to confirm this — but with an important caveat about where that transformation is happening.
95% of teams use AI in some form, and 80% use it substantially. So the question has shifted from “are you using AI?” to “are you using it for the right things?”
The answer, for most teams, seems to be no. The top AI use cases look like this:
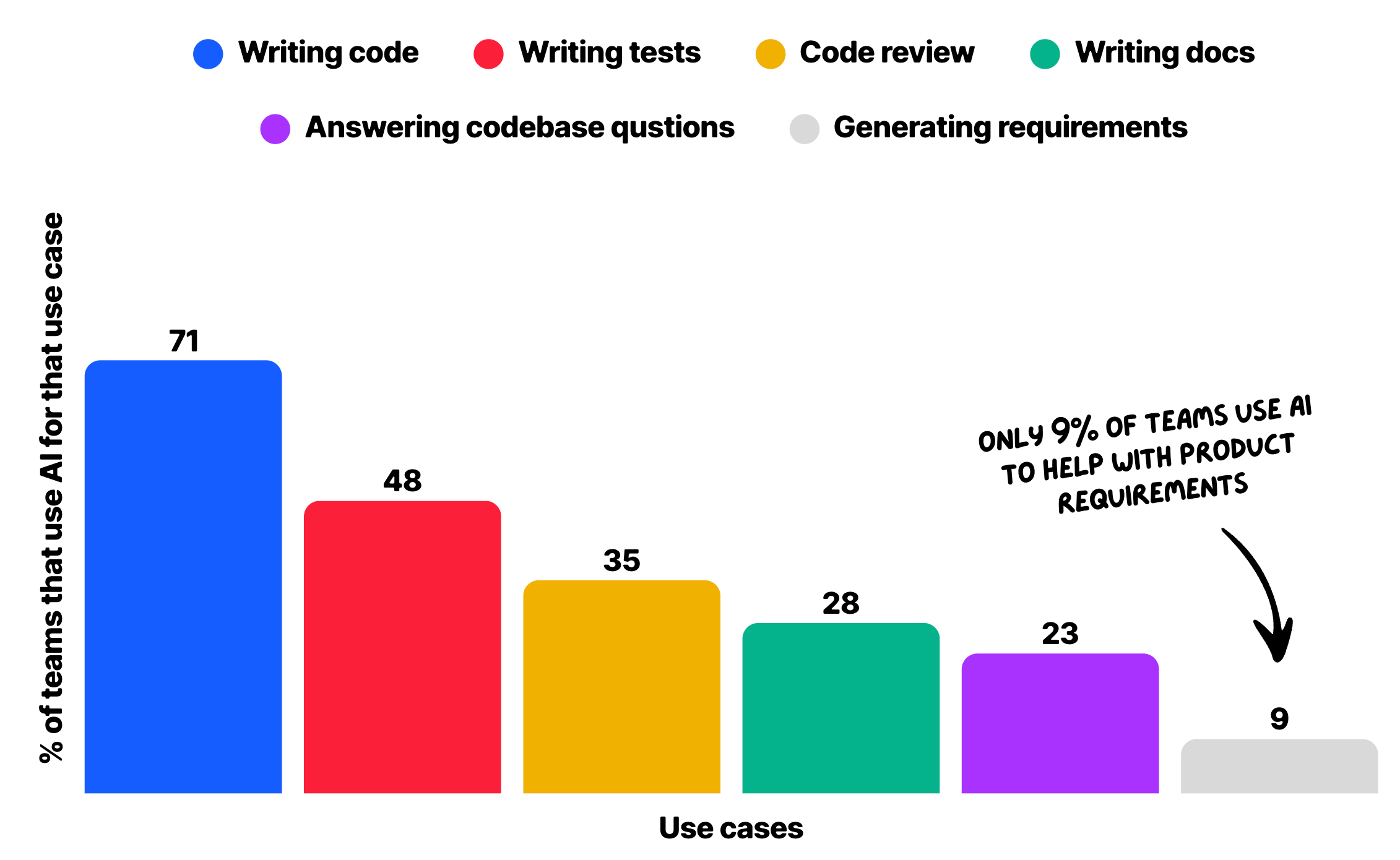
That last number is worth focusing on. Writing good requirements—the use case most directly tied to every planning problem we covered in the previous section—is used by fewer than 1 in 10 teams.
AI is being applied downstream, but a lot of problems live upstream.
Shared context is the other missing piece. When we asked how teams manage AI context, the majority answer was straightforward: they don’t.

54% said each developer manages their own prompts individually, with no shared infrastructure.
Only 29% use shared files in the repo (AGENTS.md, CLAUDE.md, Cursor rules).
Only 3% intentionally organize context in their existing docs and tickets, for AI tools to access it.
This matches what Doug, Atono’s CPO, predicted before we ran the survey:
“[What we see so far is that] the greatest consumers of AI-coding are very clever developers who piece together a number of components... so only that clever developer is excelling.”
One engineer also described the mess directly:
“If I want to leverage a Notion doc, a Slack thread, a Jira ticket, and the actual codebase […] I have to manually copy and paste relevant context into the tool I plan to use.”
— Software Engineer
If planning problems were evenly distributed across companies of all sizes, with context problems, enterprises are the ones doing significantly worse. Companies with 500–1,000 engineers have >75% of developers managing AI context individually, vs small startups at 51%. More resources don’t produce more shared practices.
People are also generally aware of this: 54% of respondents agree that most AI quality problems are actually context problems. Leadership agrees even more than ICs. So it seems this is not an awareness problem, but rather about most teams not (yet) doing intentional work to bridge the gap.
AI is also expanding what individual engineers can do. 74% of engineers say AI has helped them work outside their primary specialty, and 59% are handling more of the product process than a year ago:
Tech leads report the highest scope expansion (72%)
Engineering managers the lowest (48%)
This pattern appeared in our last report too. Classic line management hasn’t been transformed by AI yet, at least not how much ICs have.
In general, the product engineer thesis holds: AI is accelerating the shift toward engineers owning more of the full product cycle. But without shared context infrastructure, the expanded scope creates individual-level fragility rather than team-level leverage.
🧪 The Experimentation Gap
There is a clear divide in how teams approach AI learning, and it predicts almost everything else.
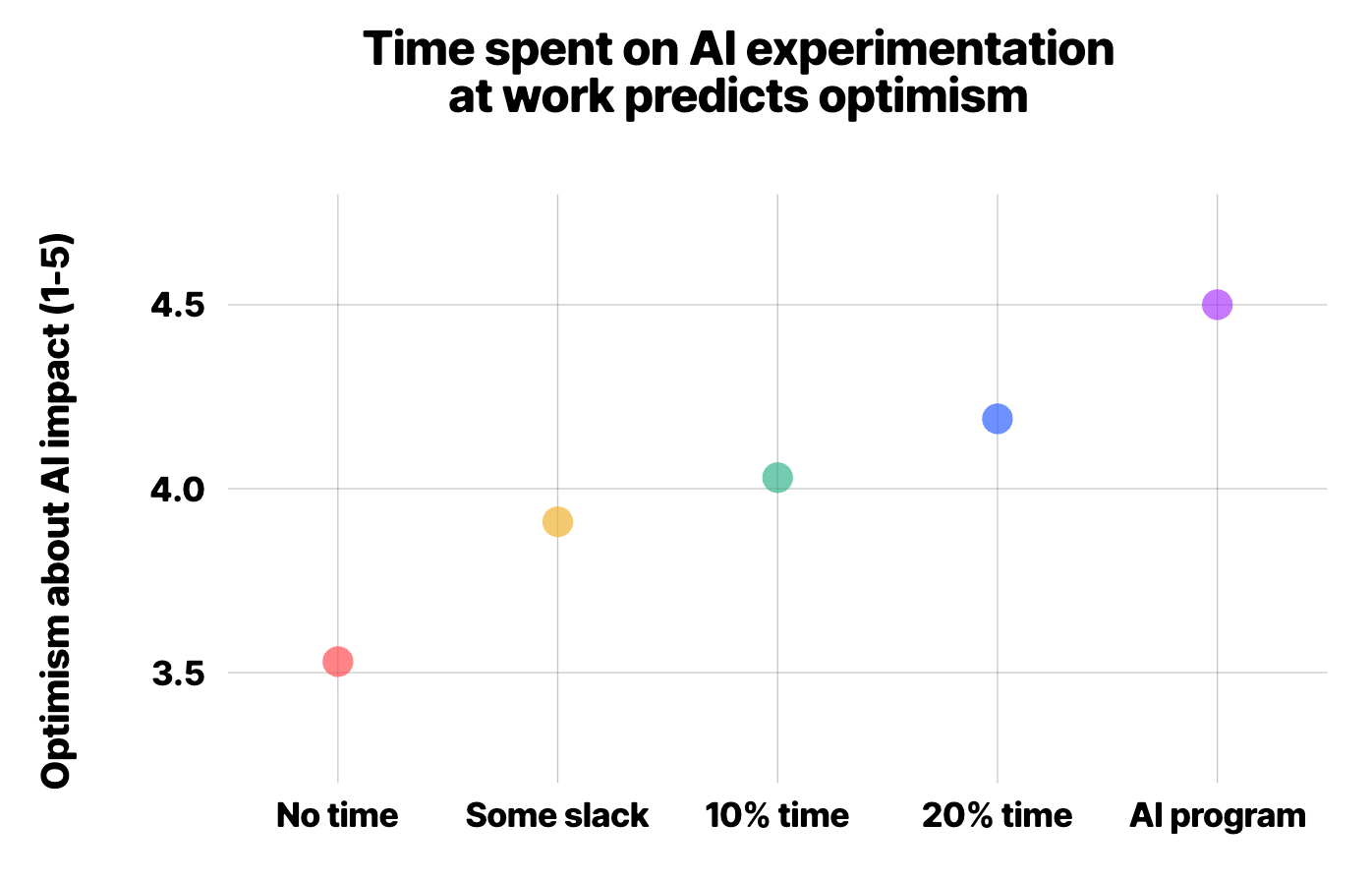
44% of teams have no dedicated time for AI experimentation at all. They do it on the side, squeezed between deadlines. 31% allow some slack informally. Only 17% have explicit, dedicated time, whether it’s a fixed share of their capacity (e.g. ~10%) or a more structured program.
Out of these cohorts, teams with dedicated experimentation time are substantially more optimistic about the year ahead and report better results with AI. This isn’t exactly a surprise: deliberate practice compounds, while winging it stays shallow.
“The usage of AI needs to be learned on the job while adhering to deadlines.”
— Software Engineer

By going through the open answers about this, the feeling is that, when AI learning happens on the side, under deadline pressure, engineers just stick to what works. This means they are more likely to get stuck into local optima, and never discover workflows that would significantly change their output. That takes trial and error, and most of all, time.
The teams getting the most out of AI are, by and large, those who have just more time to figure things out.
The possibly clearest signal about this is the optimism gap. Teams with dedicated experimentation time are significantly more optimistic about the year ahead. Those without it cluster around neutral.
In other words, time spent on in AI learning is a leading indicator: investment today predictably shows up in results later.
🔭 The Way Forward
All in all, the data in this report points to gaps that are organizational rather than technical. The tools exist. The adoption is near-universal. What’s missing is infrastructure: context, clarity, and shared practices that make these tools work.
We believe three transitions define the difference between teams that are compounding their AI advantage and teams that are stuck into running a broken process faster:
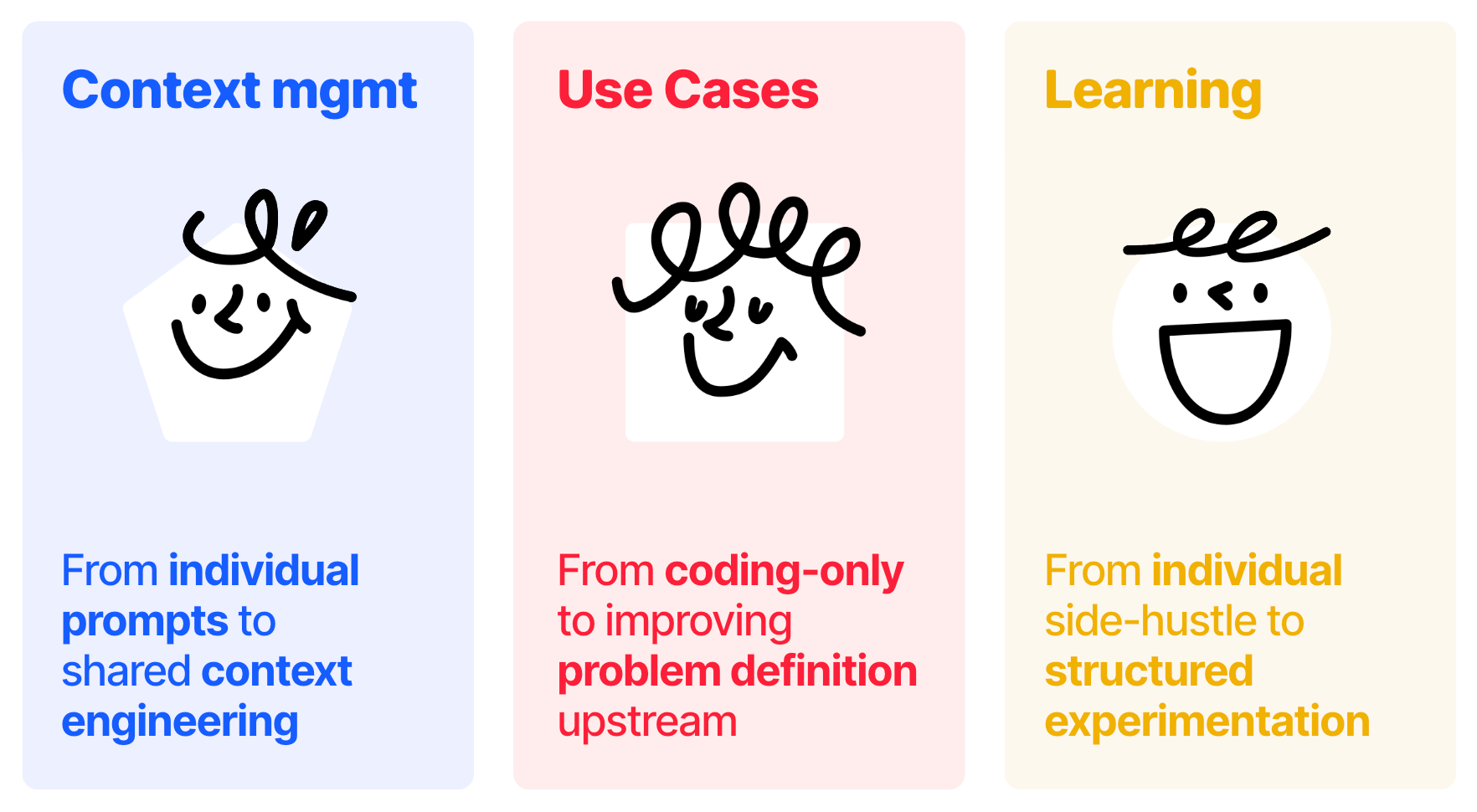
1) From individual AI usage to team-level AI context
52% of teams have each developer managing their own prompts, with no shared infrastructure. Instead, the teams pulling ahead treat context as a shared resource: documented decisions, shared prompts, and product knowledge organized so AI can actually reach it.
This requires treating context as a team asset rather than a personal one. Not a big investment, but a daily, compounding one.
2) From accelerating execution to improving problem framing
Only 9% of teams use AI to generate requirements and acceptance criteria.
This is the highest-leverage untapped use case in this entire report. Before using AI to write more code, teams should ask whether the work is well-defined enough for AI to help at all. Garbage in, garbage out. So, with AI, it’s more garbage, faster!
3) From side-hustle AI learning to structured experimentation
Half of teams have no dedicated time for AI learning. Conversely, numbers show that deliberate practice is the only path to compounding returns.
Teams that carve out even a small amount of time—10% of capacity, or a monthly experiment day—consistently outperform teams that treat AI learning as something to do between tasks.
Overall, this research confirms the role of AI as an amplifier of whatever you already have. Good context practices become great enablers. Fragile planning becomes more fragile, at higher speed. The teams that had their house in order before AI are now compounding that advantage.
The good news is that getting your house in order is not a moonshot. It starts with daily decisions being captured in writing instead of a Slack thread. One set of acceptance criteria generated before development begins. One afternoon a month to experiment with AI without a deadline attached.
The gap is real, but it’s also closable. Let’s get to work!
See you next week!
Sincerely 👋
Luca
I want to thank again Megan, Doug, and the whole Atono team for supporting this work. I am a fan of what they are building — you can check it out below 👇
One of the points raised in the post, is the lack of organization and how difficult it can be to escalate issues effectively across the structure.
In the past, when another team or person slowed you down, you often just had to deal with it. Now, many people see AI as a kind of superpower: something that allows them to move faster, depend less on others, and work around teams that may be slower or less engaged.
I think this creates a risk of people becoming more individualistic, because with fewer dependencies they feel they can go further on their own. That could gradually push the organization toward more fragmented and smaller teams.
For me, the key challenge is the facilitator role, people who can identify good practices across teams, understand what can be reused in different contexts, and help that knowledge circulate. We also need shared spaces where information is consolidated and a culture where people know how to learn from each other.
The contextual layer is especially important. It is easy to be impressed by what other companies are doing, but much harder to apply it to our own reality. Someone who understands both the context and the work happening internally can help raise the company’s overall level, both in how these tools are adopted and applied, and in how people collaborate around them.
Amazing.
We need to push developers to share context, skills and prompts