

My AI Coding Workflow
To ship high-quality software that you don't need to write (or... read).

I admit I was one of those who didn’t believe Dario Amodei when he said last year that AI would soon write 90% of the code. Instead here we are. There are indeed teams I personally know who are having close to all of their code written by AI, and are having the time of their lives.
And it’s not random teams: it’s usually the best ones. If you don’t trust my anecdotal evidence, just look at recent reports. The very best teams, who had the best DX and code quality before AI, are the same who are getting the most out of AI today.
Still, it’s not 100% clear how these teams work with AI. The internet is full of opinion pieces and people sharing their CLAUDE.md files, but these feel tactical at best, and dubious/fake at worst.
I don’t want to add more of these. The proof is in the pudding, so I said to myself: if I want to write about AI coding, I need to build something.
So here we go.
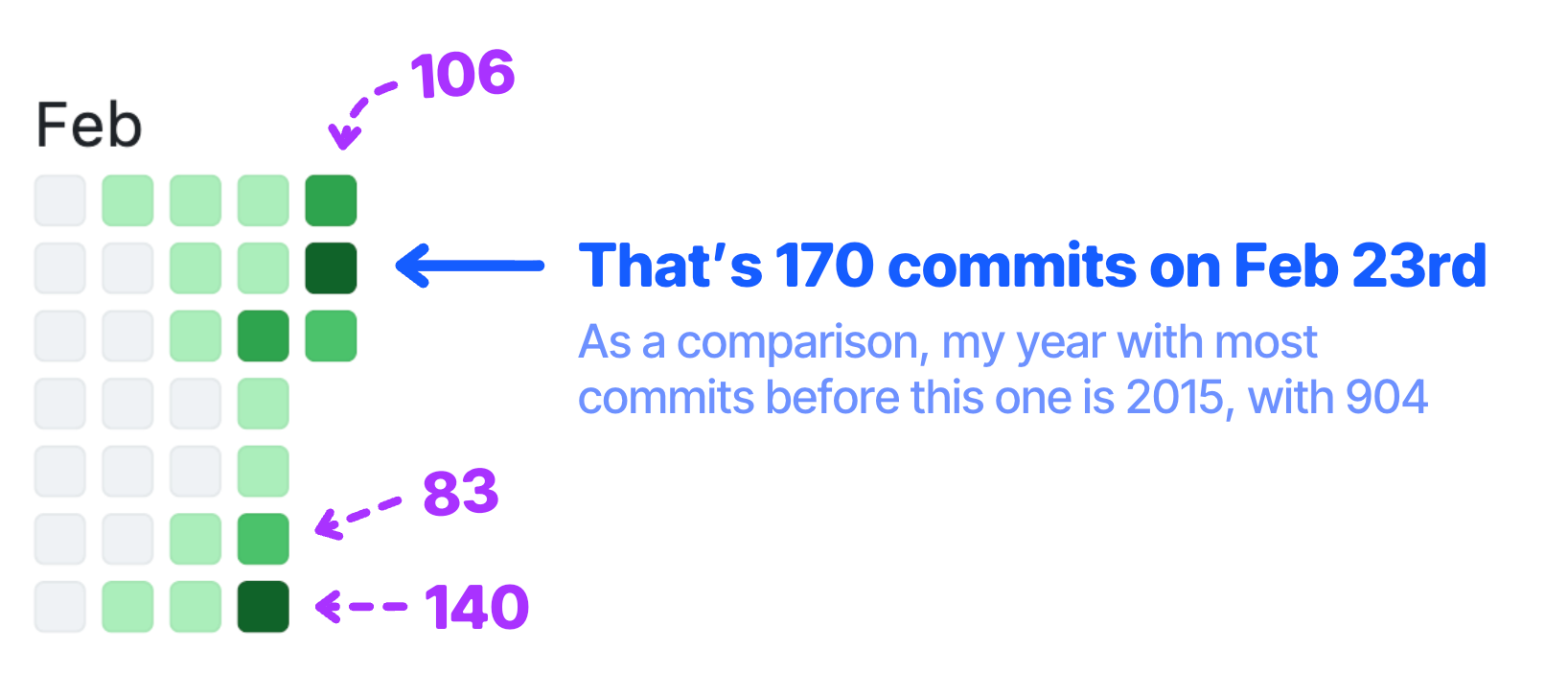
For the last 17 days, I have been working on a personal project for a macOS app. Scope and complexity are daunting enough to force me to think architecture, buy vs build, performance, rich UI, and everything I would need to cover in a real—not toy—software project. And needless to say, I would never be able to pull this off without AI.
Before I give you more details, let’s start with what I got today so far:
772 commits in 17 days, for ~20,000 lines of code overall.
90% test coverage — via 500+ unit, integration, and E2E tests.
9.3/10 code health — as measured by CodeScene.
A clear, hierarchical set of docs — to navigate architecture, abstractions, and codebase structure.
A perfectly usable MVP — which I am, in fact, using every day.
I figured out and improved various parts of the workflow over time, so that now I am comfortable with:
Not writing any code.
Not reading almost any code. Say I read ~5% of it.
Not providing UI design for ~90% of the features.
Managing most interactions async via voice notes.
Having AI work autonomously for long stretches of time, so I can do something else in the meantime.
So let’s dive into all of this, in detail. Here is what I am going to talk about:
🖥️ What I am building — because nothing else matters.
🎨 My product workflow — how I work as a PM.
🔬 How I keep tech quality — how I work as a CTO, without reading the code.
💰 How much I spent — the numbers nobody shows.
🔮 What’s next — my takeaways so far, and some obvious predictions.