



AI coding, batching meetings, cloud vs on-premise options💡
Monday 3-2-1 – Edition #38

Hey, Luca here 👋 welcome to the Monday 3-2-1 ✨
Every Monday I will send you an email like this with 3 short ideas about engineering management, technical strategy, and good hiring.
You will also receive the regular long-form one on Thursday, like the last one:
To receive all the full articles and support Refactoring, consider subscribing if you haven’t already!
p.s. you can learn more about the benefits of the paid plan here.

1) 🤖 AI coding vs open source
Coding with the help of AI assistants, like ChatGPT or Github Copilot, genuinely feels like the future.
However, while these tools are undeniably useful, I am kind of concerned about how the software space will evolve in terms of workflow and innovation, as soon as they get mainstream.
Let’s take, for example, the classic open source workflow, and compare it with the emergent AI-fueled one.
With open source, people can open up issues about bugs and changes. These issues can be seen by everybody, there is little duplication, owners reply, people have a discussion, and so forth. On top of this, fixing a bug once fixes it for all users (granted they will update their version).
That looks like a good feedback loop to me.
Let’s compare it now to the current state of AI coding.
AI coding is not based on reusing the same code, like open source, but on creating new code every time. This is like code duplication at scale, and poses the same problems.
If the AI introduces a bug on something, it will do so for all users that request that code. Those users, in turn will each have to fix the same bug by themselves.

What’s worse, right now we have no way of making the AI learn from its mistakes + our corrections. There is no feedback loop.
So, while AI is surely going to provide incredible benefits, it is also going to change some core dynamics that so far have enabled innovation, open source, and much of the software ecosystem as we know it today.
We will have to wrap our heads around this to figure out what is the best, most productive way of using AI, while also making sure we are moving forward as an industry.
You can find more thoughts about AI and the future of coding in this previous Refactoring article:

2) 🪡 Batching meetings together
A couple of weeks ago I wrote an article about how to reduce meetings that got very popular ❤️
However, reducing / removing meetings is often a strategic activity that may take several months to pay off. In the short term, you can often improve your situation by just arranging them in a smart way.
Here are three solid ways to do so:
🧘 Set aside your focus time
Many leaders I know block time on their calendar to do “maker’s work”.
This is also known as focus time.
You can use tools like Clockwise to manage this semi-automatically. It allows you to block your own focus time, and tries to arrange meetings to preserve it.
Tactics to preserve focus time include:
Scheduling meetings close to each other (but not back-to-back, which is evil)
Scheduling meetings in a way that doesn’t break productive time in half. Good examples are: right before/after lunch, end of the day, beginning of the day.
Batching meetings together with heartbeat days and no-meeting days 👇
🚫 Create no-meeting days
No-meeting days are a common tactic to create space for concentrated work. Doing so in sync with everyone on your team creates a good feeling, too.
Zach Wolfe, Senior Engineer at AWS, weighs in on this:
Having a no-meeting day (Friday) has been extremely beneficial to do creative/deep work. I schedule my work to load up Friday with ambiguous problem solving or design tasks instead of typical day-to-day coding/meetings.
🩺 Create heartbeat days
The dual strategy to no-meeting days is heartbeat days: days where you concentrate most recurring meetings.
Yurii Mykytyn, Director of Engineering at Rebbix, tells of his experience:
Monday is heartbeat day: most of my org works in weekly cycles and we mostly do weekly 1:1s, so on Monday I check-up with each of peers and everyone has a great picture of how org looks and what the week is about.
You can find more ideas about managing your time in this past Refactoring article 👇
3) ☁️ Cloud vs on-premise options
When it comes to infrastructure options, I have found that many people assume this is a simple binary choice, where you either go 100% cloud native, or you buy a noisy server and keep it in your closet.
Reality is, of course, more nuanced than that.
There are two main things you have to manage:
🔋 Physical infrastructure — machines, networking, electricity, and everything that exists in the physical world.
✨ Virtual infrastructure — virtualization, provisioning, and all lifecycle operations.
So, what options do you have to handle these?
🔋 Physical infrastructure
The possibilities here are:
Fully owned — you run your own servers in your own datacenter (or closet!).
Co-location / Housing — you run your own servers in someone else’s datacenter.
Cloud — you use servers owned by a cloud provider, in their own datacenter.
These options have ascending nominal cost and descending maintenance effort.
So, based on how effective you can be at handling maintenance you may or may not save money on any of the first two vs the full cloud.
For 99% of companies, however, running physical servers on their own should be totally out of the question. Handling electricity, networking, cooling, and security, is no joke — you probably don’t have and don’t want to build this kind of specialty on your team.
✨ Virtual infrastructure
Virtual infrastructure is what you put on top of the bare metal to handle provisioning and virtualization. You have three main options here as well:
Fully owned — with your own servers you have full control and you can use software like VMWare, Red Hat, Oracle.
Cloud — if you run on a major cloud provider, you transparently use their own system. They handle everything for you.
Hybrid — it is little known but you can run (parts) of the virtualization stack of major cloud providers on your own servers. E.g. with AWS Outposts, a physical server of yours can run the AWS control plane, and you see it as a Zone on your AWS console. Kind of similarly, with Google Anthos you can run K8s clusters on a server of yours and manage them from your GCP console alongside your other GCP services.
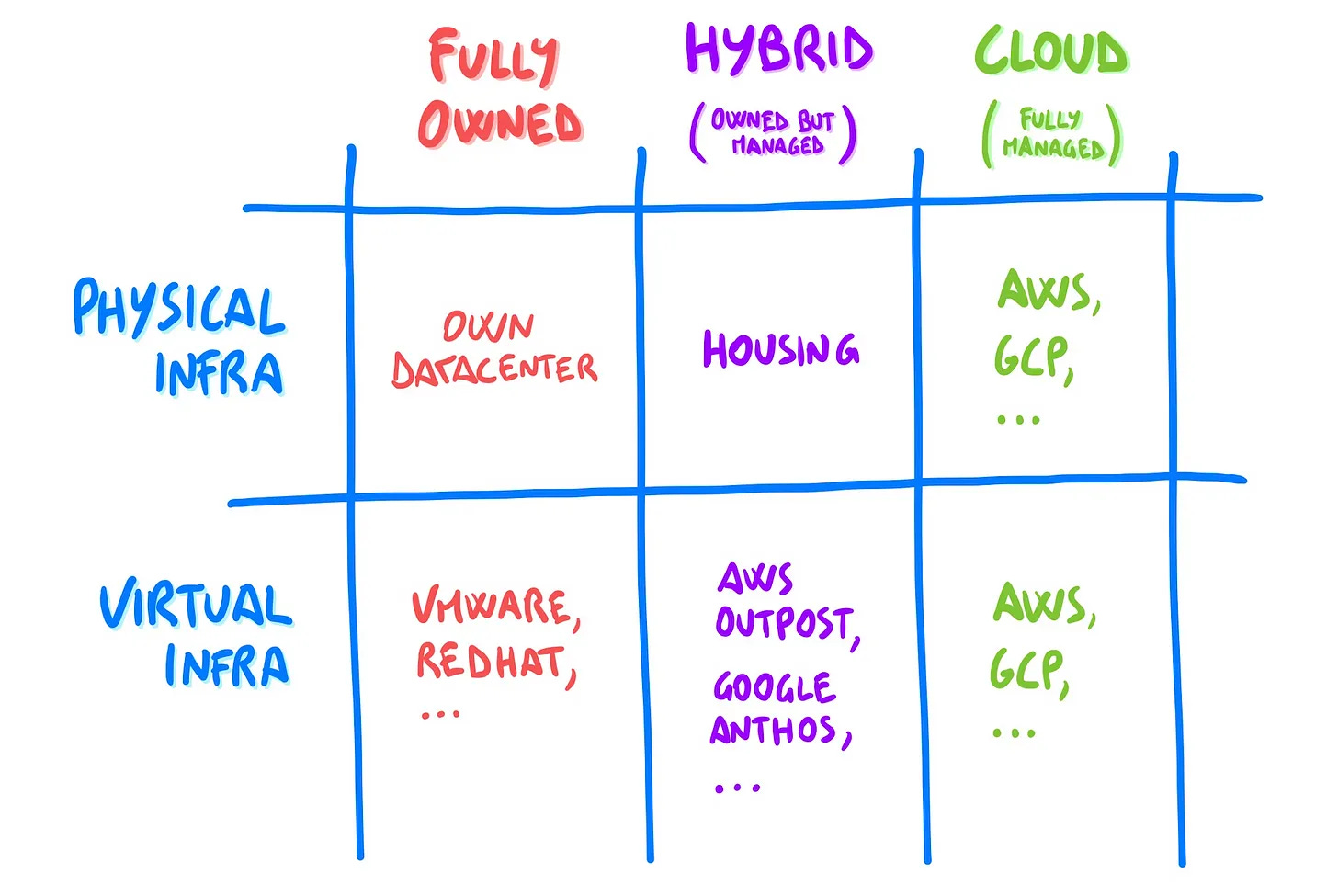
You can find more info about these tradeoffs, and how to choose between the various options, in this previous article:
And that’s it for today! If you are finding this newsletter valuable, consider doing any of these:
1) ✉️ Subscribe to the newsletter — if you aren’t already, consider becoming a paid subscriber. You can learn more about the benefits of the paid plan here.
2) ❤️ Share it — Refactoring lives thanks to word of mouth. Share the article with your team or with someone to whom it might be useful!
I wish you a great week! ☀️
Luca