

How to Manage Context in AI Coding 📑
Exploring an evergreen art, made 10x more relevant by AI

Last month I had the privilege to keynote at the CTO Craft Conference in Berlin, where I tried to paint a broad picture of how engineering teams are using AI today.
To prepare for the keynote, I did a lot of research. I started with our own survey data from the newsletter, but I also took stories from our podcast interviews, plus ad-hoc 1:1s with tech leaders who I knew made good use of AI.
As I eventually said in the keynote, all this data proved a bit inconclusive. For some teams, AI is a runaway success. For others, it’s nice to have at most.
Assuming—as I do believe—that both camps are right in assessing the impact of AI on their teams, the next question is obvious: what separates the early winners from the rest of us?
In recent weeks we have often said that what’s good for humans is good for AI — so AI, for the most part, acts as an amplifier, making good teams even better, and increasing the gap with average ones.
But it would be simplistic to say that’s all there is. There are indeed AI-specific things that teams are doing to work better with it — many of them are tactical and probably transient, but there are a few that feel foundational and here to stay.
The most interesting one, to me, is context engineering.
Context engineering is a relatively new term, initially popularized by Tobi Lutke and Andrew Karpathy, and then picked up by many others.
I really like the term “context engineering” over prompt engineering.
It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.
— Tobi Lutke, CEO of Shopify
It started as an attempt to go beyond prompt engineering, which, if you ask me, never felt completely right 👇
Merely crafting prompts does not seem like a real fulltime role, but figuring out how to compress context, chain prompts, recover from errors, and measure improvements is super challenging — is that what people mean when they say “prompt engineer?”
— Amjad Masad, CEO of Replit (in 2023!)
Prompt engineering ideas feel like tactical advice at best—focus on the how, tone, structure, rather than actual outcome—and magical incantations at worst (”You are an expert...”, “Let’s think step by step”).
So how is context engineering different from prompt engineering? First of all, I believe “context” is a better abstraction than “prompt”:
📑 Providing the right context — conveys the idea of grounding the model into accurate and exhaustive information.
🪄 Providing the right prompt — conveys the idea of nailing some specific wording.
You might argue it’s just words, but words matter: over the long run, I believe we want teams to focus on good context, rather than good prompts.
Context engineering, then, should refer to the discipline of designing systems and workflows that reliably ensure AI is provided with such right information.
But what makes this a system, worthy of the engineering word? To me, it’s about two qualities:
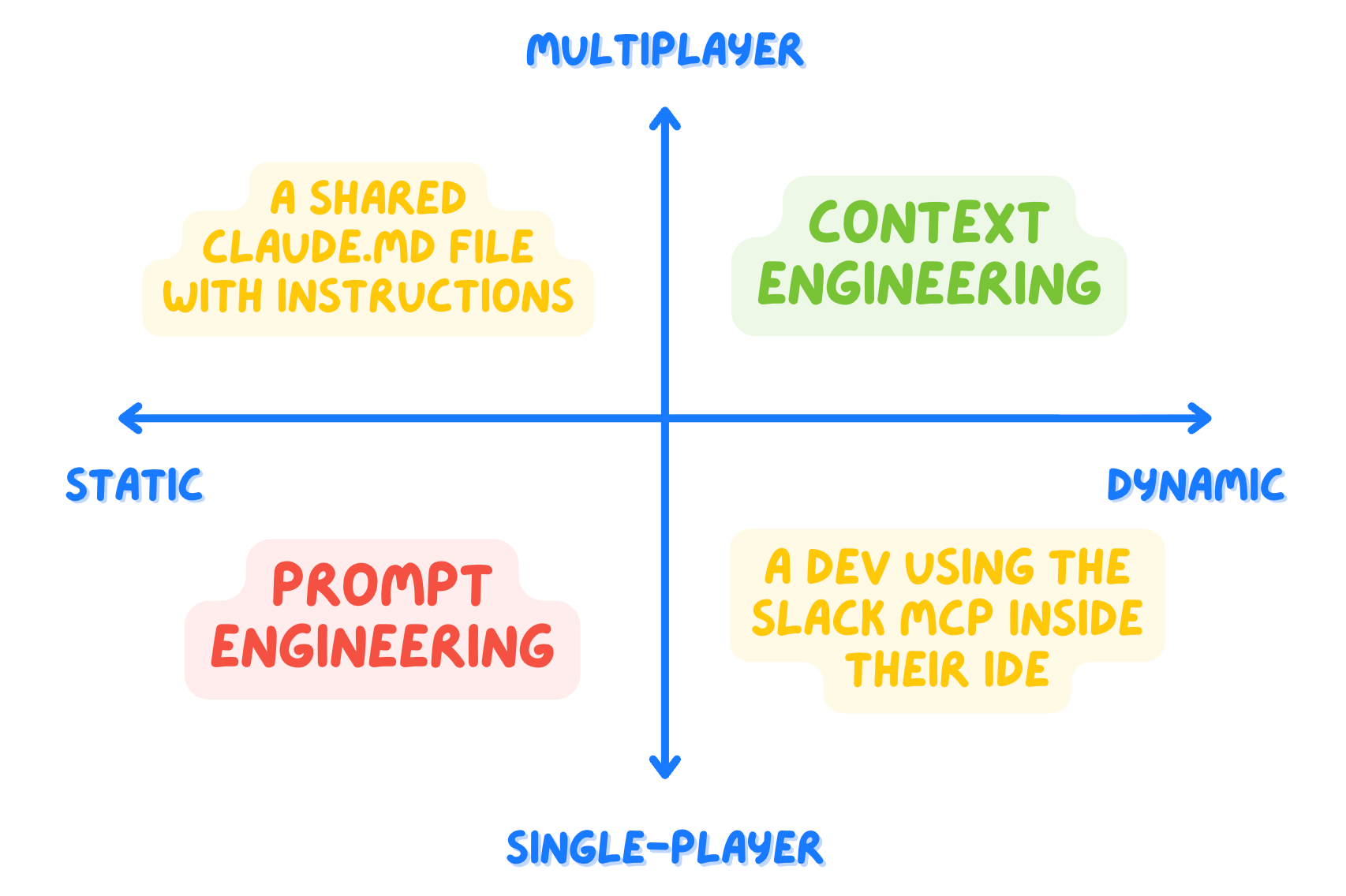
👯♀️ Multi-player — it should be designed with the team in mind. Shared workflows and practices.
⚙️ Dynamic — it should enable AI to fetch the right content by itself as much as possible, rather than humans passing it every time.
Note that these qualities are orthogonal. In fact, you can work in modes that are:
Dynamic but single-player — a zealous developer who configures 10+ MCPs on their single Claude Code installation.
Multi-player but static — a giant shared CLAUDE.md file that contains a lot of info about the repo.
So let’s explore this in a more systematic way, with a particular focus on coding workflows. Here is the agenda:
✅ Tasks vs procedures — what do people (and AI) need to know to do… things?
🔭 Sharing the why — the often neglected part.
📖 Task-relevant context — separating between mandatory and best effort context.
🤏 Keep context small — to keep your life simple.
Let’s dive in!