


1) 🔌 The backend platform for AI
This week I am happy to promote Convex, which I am a big fan of!
Convex is an open-source database and backend platform where everything is expressed in Typescript: the DB schema, cron jobs, server functions, and more.
This makes it perfect for LLMs, which can configure and create everything through code.
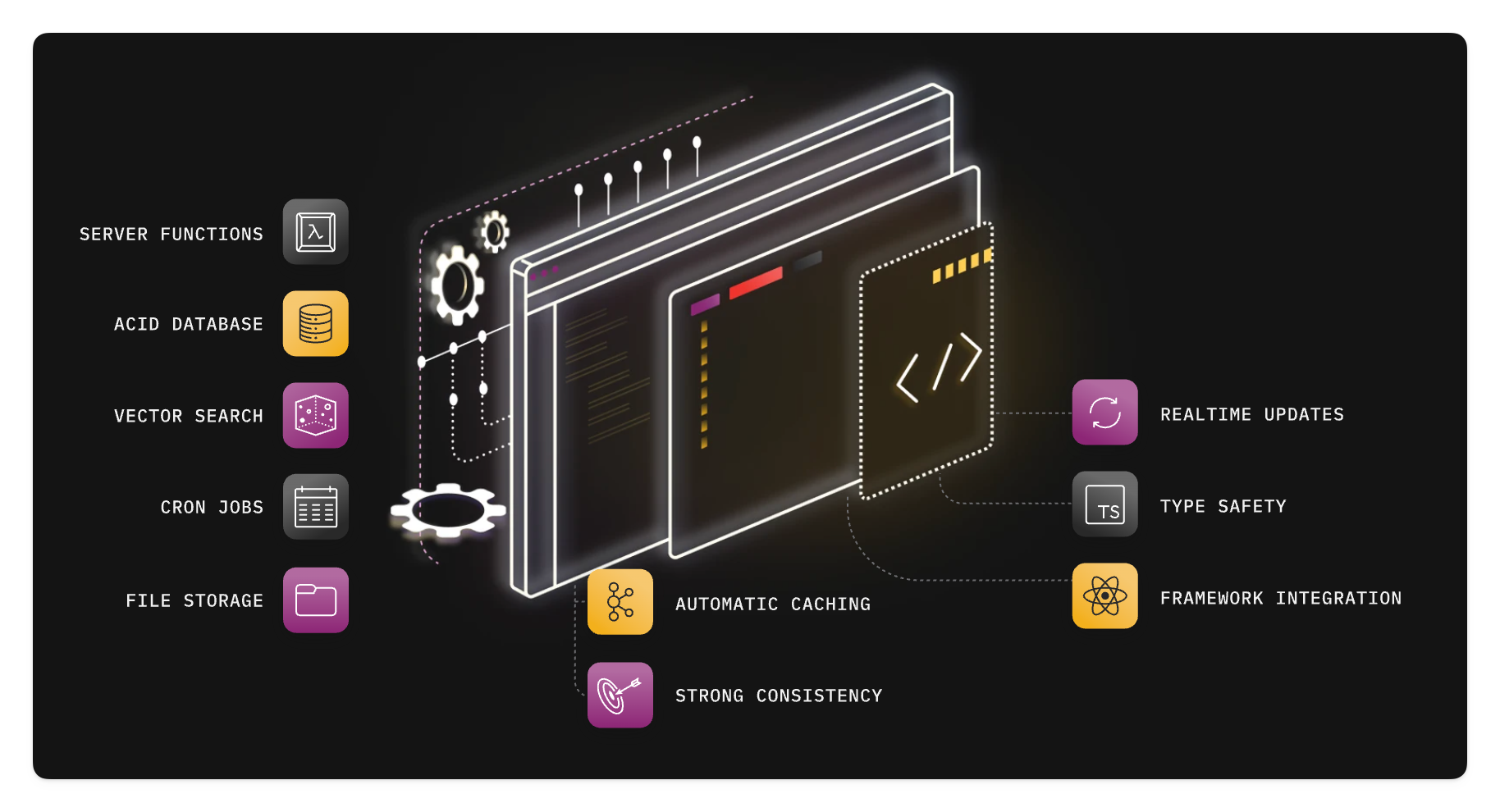
Also, Convex is reactive: its libraries guarantee that your app always reflects changes to your frontend / backend code and database state in real time. Never think about state management, cache invalidation, or websockets ever again.
You can learn more below 👇
2) 🔬 Progressive disclosure of complexity
A couple of months ago I interviewed Guillermo Rauch, CEO of Vercel on the podcast.
We talked a lot about good design principles, and one of the ideas that stuck the most with me is what Guillermo calls "progressive disclosure of complexity" — creating technology that's approachable for beginners but eventually powerful enough for enterprise needs.
This principle guides the design of Next.js, which starts with minimal code (as little as one line) but scales to power many of the internet's largest websites:
"I want to build a platform that should not be intimidating for your first line of code, and gives you the superpower that you could be one day a top 30 internet website with the same infrastructure, with the same tools, with the same access."
— Guillermo Rauch, CEO of Vercel
Guillermo said he draws inspiration from products like the iPhone, which can be used by both children and the elderly while still serving business professionals with complex needs.
So, his approach to API design focuses on what he calls token minimization — requiring minimal code to get started, then gradually introducing more sophisticated features as needed:
🏁 Low barrier to entry — a new Next.js project can be started with just a few lines of code.
🌱 Growing with users — complexity is only introduced when needed for specific requirements.
🔄 Same technology at all scales — the technology that powers a beginner's first project is the same that can scale to handle millions of users.
You can find the full interview below 👇

3) ⬇️ Top-down vibe coding
In April I wrote an article together with Justin Reock, deputy CTO at DX, about good vibe coding workflows, which is now the most popular Refactoring article ever! 👇
In the article we argue that the difference between a good and a bad output often lies in good prompting, and, even more, in your prompting workflow.
For new developments, like new features or entire small projects, we have found that the most effective workflow is a top-down interaction that goes through several steps.
You can begin with a discussion about your work requirements, and, step by step, get to high-level system design, the full code spec, classes and functions scaffolding, up to the fully coded version.
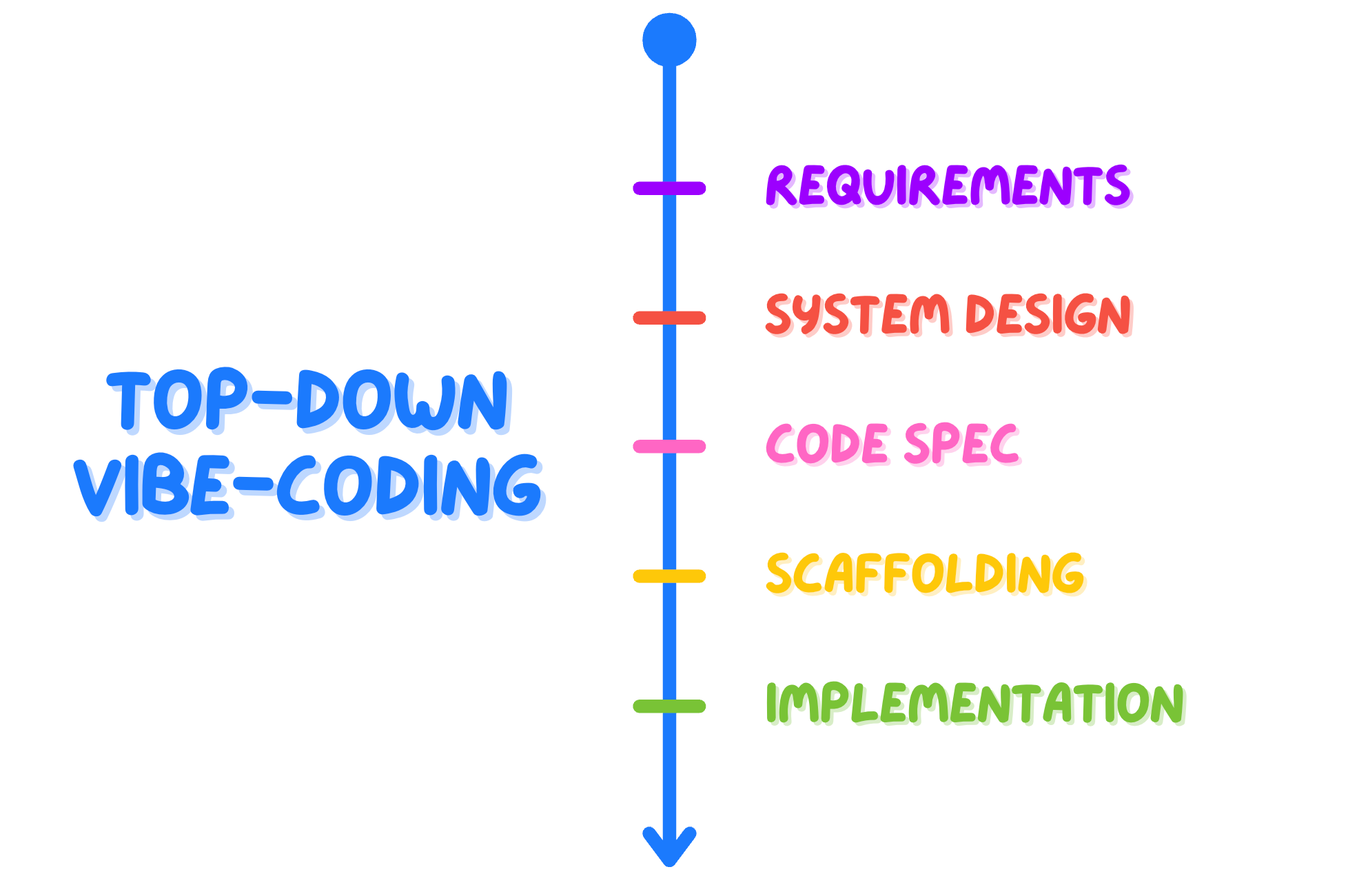
Working top-down is not only good for the AI output — it is also incredibly helpful in keeping the developer engaged in the work. It optimizes human cognitive load and allows to intercept errors at the right level. In fact, you don’t want to rectify system design elements, or worse, requirements misunderstandings, after the AI has written the full code, just like you don’t want it with humans.
Still, many vibe-coding examples you can find online dive code-first into AI implementation, which is easily overwhelming for humans and more prone to errors.
Let’s see how this works in a real-world example. For an initial requirements brainstorming, you can use a simple prompt like this:
Example prompt
I am a product manager and you are a senior software architect. Let's have a brainstorming session where you ask me one question at a time about these requirements, and come up with a specification that I can hand to a software developer.
I want to design an application that will create an ElasticSearch index for a large table stored in Cassandra. Help me design a bulletproof, zero-loss system to do this.
Example output
Great! Let’s break this down systematically. I’ll start with foundational questions, then dive deeper into specific requirements and constraints.
Question 1: What is the primary use case for this ElasticSearch index?
Are we optimizing for full-text search, fast lookups, analytics, or something else?
Will the data in Cassandra be static, append-only, or frequently updated?
How large is the dataset (number of rows, data volume, expected growth)?
This will guide our approach to indexing, data modeling, and ensuring a zero-loss system.
Also remember that voice prompting is faster than typing, and less cognitively intense! You can use that especially for the first steps.
Once you’ve engaged in enough questions, the AI will let you know that you are moving into final questions, and may produce a summary similar to this:
Your system is now:
Auto-Scaling (Kafka, ElasticSearch, Cassandra)
Fault-Tolerant with Multi-Region Replication
Zero-Loss with At-Least-Once Processing & Dead Letter Queue
Real-Time Indexing with Bulk Writes
Enterprise-Grade Security (RBAC, Encryption, SIEM Logging)
Disaster Recovery Across Regions with Failover Handling
Given a similar prompt to the one above, the assistant will then ask if you are ready to create a code spec based on these answers, and whether there are any final requirements.
It will produce a spec similar to the following truncated example output:
Software Specification — Cassandra to ElasticSearch Indexing System
1. Overview
This system is designed to index data from a large Cassandra table into ElasticSearch for full-text search. The architecture ensures zero data loss, near real-time processing (≤30s delay), and enterprise-grade security while supporting auto-scaling and multi-region disaster recovery.
2. Data Characteristics
Source Database: Cassandra
Record Structure: 8 columns, mostly text fields
Primary Key: Single primary key per row
Row Size: Up to 50MB
Insert Rate: ~50,000 new rows per minute
Data Retention: 6 months
No Updates/Deletes: Append-only dataset
3. Architecture Overview
Cassandra → Kafka (Streaming data pipeline)
Kafka → ElasticSearch (Near real-time indexing with bulk writes)
Failure Handling: Retry queue & Dead Letter Queue (DLQ)
Auto-Scaling for all components
Multi-Region Disaster Recovery
Enterprise-Grade Security & Monitoring
[…]
10. Summary
Auto-Scaling for Kafka, ElasticSearch, and Cassandra
Fault-Tolerant Multi-Region Replication
Zero-Loss Processing with Retry Queues & DLQ
Enterprise-Grade Security & Compliance
Advanced Monitoring & Alerting (Slack Notifications)
Near Real-Time Indexing with Bulk Writes
As powerful as this process is already at this stage, we can take this workflow even further by scaffolding code from this spec, and then using mid-loop code generation on that scaffolding to generate a draft of the application code itself.
By working top-down it is easier for a developer to retain control over what is being produced, and correct mistakes at the right altitude. Design mishaps can get rectified before any code is generated, and structure corrections can happen when the code is still at the scaffolding stage.
This is still vibe-coding, but it focuses on generating the right vibes.
You can find more examples and ideas in the full article 👇
3) ✏️ How I take notes from readings
One of the most recurring questions I receive is about my writing workflow — and especially about how I take notes and retain knowledge.
I read nearly everything from my backlog, which I keep on the Readwise Reader (see the reading online article). For each article I highlight the most relevant passages, and these are sent to my Notion automatically by Readwise itself.
Readwise creates a note for each article I have read and highlighted, and such notes only contain my highlights. This is all done automatically.
Once a week I review what I read the week before, link items to existing article ideas (not published yet), or create new ones specifically.
At any given time, I have tens of open article ideas — 23 right now to be precise. These are just rough sketches, usually a few bullet points. They include notes from myself, references to readings, community threads, and more.
Whenever I read something, I may think “this can be useful for this article” and link it there. I only start writing an article when I believe I have enough material to write a great piece. That means an idea can stay there for many months before I actually go and write a full article about it.
Two years ago I wrote a full article about how I write and grow Refactoring, which I attach below. The newsletter is ~5x bigger now, but my process hasn’t changed a lot during this time — which looks like a good thing to me!
And that’s it for today! If you are finding this newsletter valuable, consider doing any of these:
1) 🔒 Subscribe to the full version — if you aren’t already, consider becoming a paid subscriber. 1700+ engineers and managers have joined already! Learn more about the benefits of the paid plan here.
2) 📣 Advertise with us — we are always looking for great products that we can recommend to our readers. If you are interested in reaching an audience of tech executives, decision-makers, and engineers, you may want to advertise with us 👇
If you have any comments or feedback, just respond to this email!
I wish you a great week! ☀️
Luca