

Your dashboards are probably doomed 🖥️
Why dashboards are the wrong way to make data actionable, and how to do better.

As engineers, we love numbers and data-driven work. This starts with software, and easily translates into wider systems thinking that can be applied to processes and teamwork.
So, numbers can be powerful. However, just having them, without knowing how to operationalize them or what kind of change to drive is not particularly useful.
To bridge this gap, today I brought in Dylan Etkin. Dylan is a former development manager at several Atlassian products, including Jira, Bitbucket, and StatusPage. Today he is co-founder & CEO of Sleuth, whose mission is to provide teams with an operating system for running engineering.

Also, Dylan hates dashboards.
We spoke about this a few weeks ago, and we rapidly sketched out the main ideas for this piece. Dylan has incredible experience + strong opinions, which are usually the best premises for a great article.
Here is what we will cover today:
🙅♂️ Dashboards are doomed — why most dashboards are destined to fail.
🔄 The Metrics’ Lifecycle — the three steps to successfully using data.
🔌 Attaching Metrics to Rituals — how to use ceremonies to anchor how you use data.
Let’s dive in!
Disclaimer: I am a fan of Sleuth and what Dylan is building, and they are also a long-time partner of Refactoring. However, you will only get my unbiased opinion about all the practices and services mentioned here, Sleuth included.
You can learn more about Sleuth below. Also if you mention you are a Refactoring subscriber, Dylan and the team will give you an additional discount 👇
🙅♂️ Dashboards are doomed
For most of my career, I was surrounded by dashboards. I mean, who doesn't love a good one? It brings data right at your fingertips and makes you feel anyone can self-serve information at anytime.
In reality, dashboards are less useful than people think.
In fact, let’s look at the two types of data that typically get plotted:
🔧 Operational info — real-time, time-sensitive data to spot anomalies and incidents. This is typically very technical.
💼 Business KPIs — with goals and progress, to plot trends and trajectory.
In both cases, dashboards — as in, data always in your face — are suboptimal:
For real-time decision making, like in the case of incidents, you want alerts and push-style interaction, rather than relying on you looking at things to figure out that something is wrong.
For business KPIs, instead, you probably do periodic reviews, so you may just as well create periodic reports.
Dashboards, other than being the wrong way in which you get exposed to data, also fall short of what you need to do next:
Dashboards don't come with interpretation — the same data can mean different things to different people.
Dashboards are not actionable — they alone don't offer any sense of what action to take or outcome to change.
Dashboards don't have a review date — they don't include what you decided to do with some data at a given point in time. Often, important data can pass by without notice and just end up in a bar chart showing the past.
Dashboards can easily go stale — and for anyone who doesn't own the dashboard it can be difficult to know if the data is relevant any longer.
You may find ways to fix some of these, but in my experience it is extremely hard to design a dashboard that is truly useful and that stays so for a long time.
So, the typical cycle is: 1) dashboard gets created under the best intentions, 2) people look at it for a while, 3) not much happens most of the time, 4) some data becomes stale, 5) people notice and start caring even less, 6) dashboard gets ignored entirely.
The problem is in (3): nothing happens most of the time. In fact, people expect dashboards to deliver improvements — but they can’t by themselves because they are only artifacts, while improvements are driven by process 👇
📈 The Engineering Data Lifecycle
Making data useful, in my experience, requires a three-step process: 1) collect the data, 2) converge on interpretation, 3) drive the interpretation to outcomes.
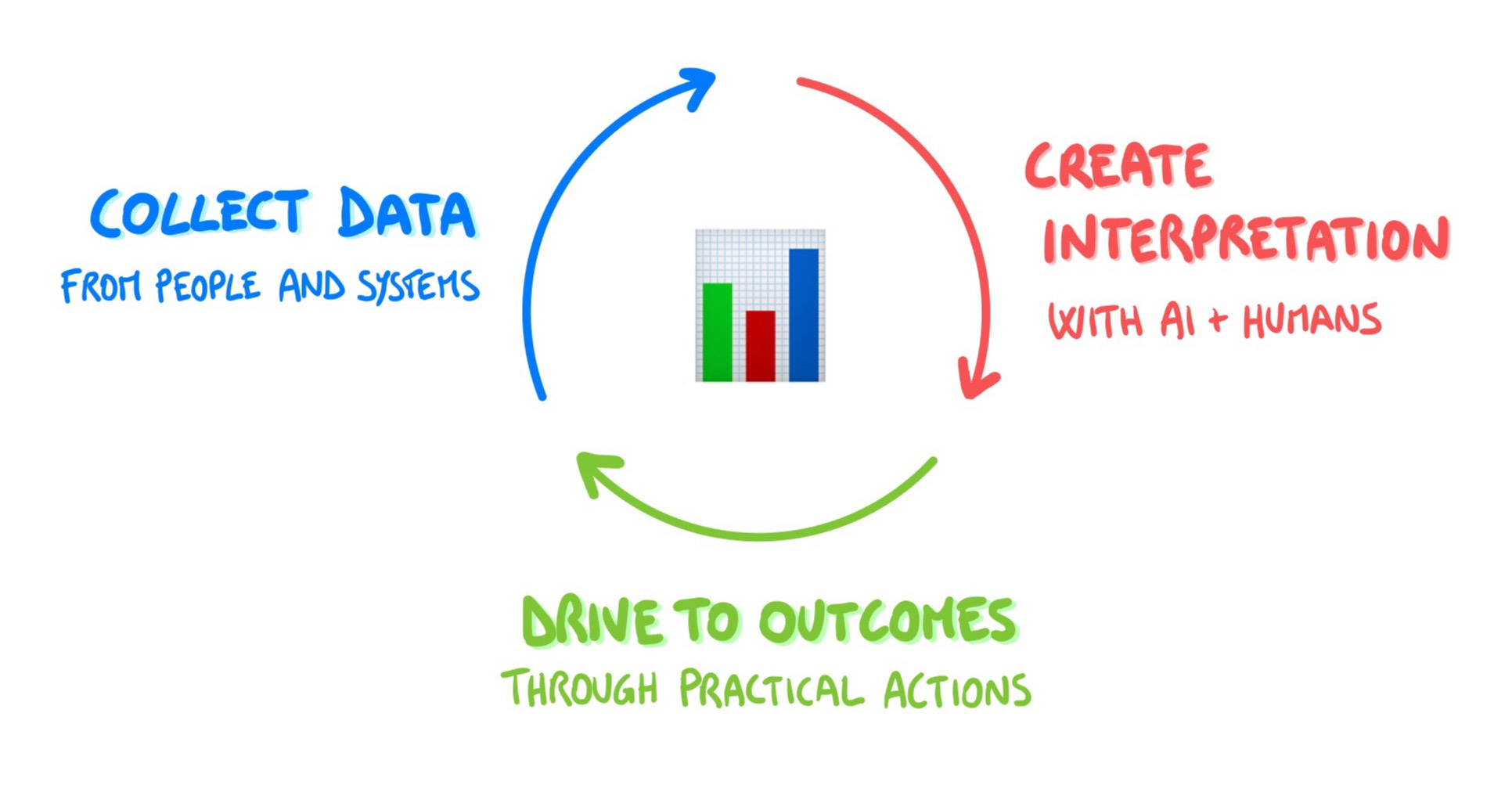
This is true for any data-driven process, but for the sake of this piece let’s stick with engineering data:
1) Collect data 🗳️
Data is available in many shapes and forms. To get the full picture, you need to take it from two sources:
🙋♂️ People — qualitative data, through surveys and conversations.
🖥️ Systems — quantitative data, through systems + good instrumentation.
Some of my favorite data to collect is:
Delivery metrics — e.g. DORA, PR lifecycle
Engineering allocations — how much time goes into KTLO, improvements, new feature work.
Operational excellence — incidents, response times, SLOs, etc.
Wellbeing — devex surveys, cognitive load, developer busyness, etc.
2) Shared interpretation 🔍
Next you need to build a shared understanding of what the data means. This is increasingly being done by AI + humans:
AI does a first pass — interpreting signal from the noise, especially in larger data sets and high-cardinality data.
Humans make sense of it — they converge on interpretation and gain consensus among the right stakeholders.
3) Drive to outcomes 🏆
Now that you have data and a shared understanding of what it means, you should decide what to do about it and how to hold people accountable to outcomes:
Capture the actions you want to take — ideally in your existing systems, e.g. Jira, OKRs, Notion, etc.
Associate those actions/outcomes with its data — what do you expect to change? Why?
Track the progress — of those actions/outcomes in a repetitive ritual so they stay top of mind and you truly drive change.
Out of these three steps, I have seen teams mostly struggle with (3).
Tracking progress is not only crucial to staying on the right track about the current actions — it is also the main way you find new actions and opportunities.
So how do you do that? 👇
🔄 Attach metrics to rituals
Most teams have repetitive rituals within Engineering but most don't include metrics reviews.
Examples are: Sprint reviews, Operations reviews, Weekly planning/status reviews, Quarterly Planning reviews, Exec eng/business alignment reviews, and more.
Many of these meetings have some documents to support it but the process of collecting that information is often ad hoc, inconsistent and cumbersome (e.g. how often have you had to herd cats by constantly pinging all the people working to put together the information and interpretation you are working on?)
A better way to adopt metrics, measure and change your engineering outcomes is:
Identify and track the key metrics that your org needs right now
Use tooling to enable and facilitate collaborative interpretation of your metrics
Review your metrics and interpretation in your orgs existing rituals
Capture actions/outcomes, attaching data to each and revisiting until you've completed or discarded the action/outcome
Let’s make a few examples:
1) Weekly review ☀️
A weekly demo/review is useful to check delivered work, check how you're doing on your objectives, and possibly steer the ship.
There is a lot of data that can help with this:
A small devex survey to check the temperature of the team — even simple “traffic lights” work: green / yellow / red.
Status for each stream of work — may include delivery metrics, like DORA.
KTLO work and impact — e.g. support escalations, bugs, incidents.
Issue breakdowns by epic and type (KTLO vs new features vs improvements vs productivity)
PR lifecycle data — especially outliers.
You shouldn’t discuss all of these items one by one in the meeting. For many of these, automatic data collection should give you the pulse of whether there’s something worth discussing (e.g. an outlier, some bad trend) or it’s business as usual.
If you are a tech leader, a good workflow is you checking KPIs before the meeting, possibly add an item or two to the agenda based on findings, and use data to start/back conversations.
2) Quarterly planning 🔭
Quarter planning is where you connect business goals to product/engineering projects.
Crucial data here is resource allocation: what do your teams spend time on? There are at least two dimensions to this:
By project — are projects correctly sized? Do FTEs match the cost we want to spend wrt the business goal?
By type — how much time goes into new projects vs improvements vs maintenance? How much control do we have over how we spend our time?
Historical data, collected automatically, builds awareness around planned vs unplanned work, trends over time, and helps you create better plans, grounded in evidence.
3) Monthly retrospective 🗳️
Many teams also have intermediate cycles, e.g. monthly retrospectives, which in my experience work well as moments of reflection that sit in between weekly tactics and quarterly strategy.
Without these, in fact, the risk is your gap is too wide: the weekly cycle is not the right place for retros, as there aren’t usually enough learnings that build up in a week. Also discussing too many things every single week creates overhead. At the same time, though, three months is a long time, and you may benefit from a structured, more thoughtful checkpoint in between.
Monthly retrospectives can serve as a good in-between where you reflect on how you have been working, get feedback from the team, and improve.
In my experience, weekly reviews are where you use numbers to discuss outliers, while monthly is where you discuss trends. This is true both for qualitative (things that came up in 1:1s, or devex surveys), and quantitative data.
The goal is to take a step back, look at all these clues about how you have been working — including people’s own opinions, and have an honest conversation together.
📌 Bottom line
And that’s it for today! Here are the main takeaways:
📊 Dashboards often fail — because they lack context, actionability, and regular updates.
🔄 Implement a three-step data lifecycle — so, instead, collect data from people and systems, build a shared interpretation (using AI + human insights), and drive it to outcomes by capturing actions and tracking progress.
🗓️ Attach metrics to existing rituals — e.g. weekly reviews, quarterly planning, monthly retrospectives, to ensure regular review and action on key data points.
🛠️ Use tools — that facilitate collaborative interpretation of metrics and automate data collection, allowing teams to focus on insights and improvements rather than manual data gathering.
Dylan and the team at Sleuth have been working on creating the operating system for engineering teams.
You can learn more about Sleuth below. Also if you mention you are a Refactoring subscriber, Dylan and the team will give you an additional discount 👇
I wish you a great week!
Sincerely
Luca
Good ⲓ don't care.