


🖥️ Enterprise Ready Conf • by WorkOS
Today we are promoting The Enterprise Ready Conference — a one-day event in SF for product and engineering leaders shaping the future of enterprise SaaS.
The event features a curated list of speakers with direct experience building for the enterprise, including OpenAI, Vanta, Dropbox, and Canva.

Topics include advanced identity management, compliance, encryption, and logging — essential yet complex features that most enterprise customers require.
If you are a founder, exec, PM, or engineer tasked with the enterprise roadmap, this conference is for you. And best of all, it’s completely free since it’s hosted by WorkOS!
Back to this week’s ideas!
1) ✨ Nurture simplicity
As engineers (or human beings, really) we want to look smart and be proud of ourselves, and it’s easy to conflate that with building complex stuff.
But simplicity is hard. It requires an elegant mental model — you can’t duct-tape simplicity.
The best engineers I have known write code like a toddler. But writing simple code requires letting go of some ego. You need experience and maturity to do the simple thing and not think that’s because you are dumb, or because you couldn’t figure out the complicated thing.
As a team, you can nurture this spirit. Simplicity comes natural when you reward shipping value to customers, and make people own the creation of such value.
In the absence of this, people may build things for the sake of it. When engineers do not participate in company goals, don’t know what they are truly working for, or just receive tickets from managers to complete, they detach. They play the game.
I wrote a full guide about planning and executing projects right, and simplicity is a big part of it 👇

2) 🎯 Strategy, goals, and projects
Ambitious work starts big (e.g. your mission) and always needs to be broken down in smaller pieces, to be distributed across teams and individuals.
This simple need led over time to a proliferation of concepts, which often have confusing relationships, like goals, projects, or strategy.
Here are my basic definitions for them:
Strategy 🗺️
Strategy is how you achieve the mission — it’s how you plan to get there. We wrote two pieces about technical strategy that you may want to check out 👇
Good Strategy / Bad Strategy — our review of the famous book of Richard Rumelt
Interview with Anna Shipman — Anna is CTO at Kooth and former technical director of the Financial Times. Our chat largely revolved around good (and bad) technical strategy.
Goals 🎯
Goals are measurable milestones that tell you that what you are doing is successful and goes in the right direction.
If you want to reach 1M ARR over the next 6 months, that’s neither a strategy nor a project: it’s a goal. It’s one of the ways you measure progress.
Projects 🔨
Projects (and tasks, and possibly levels in-between) live on the same imaginary line that answers to “how?” when you go to the right, and “why?” when you go to the left 👇
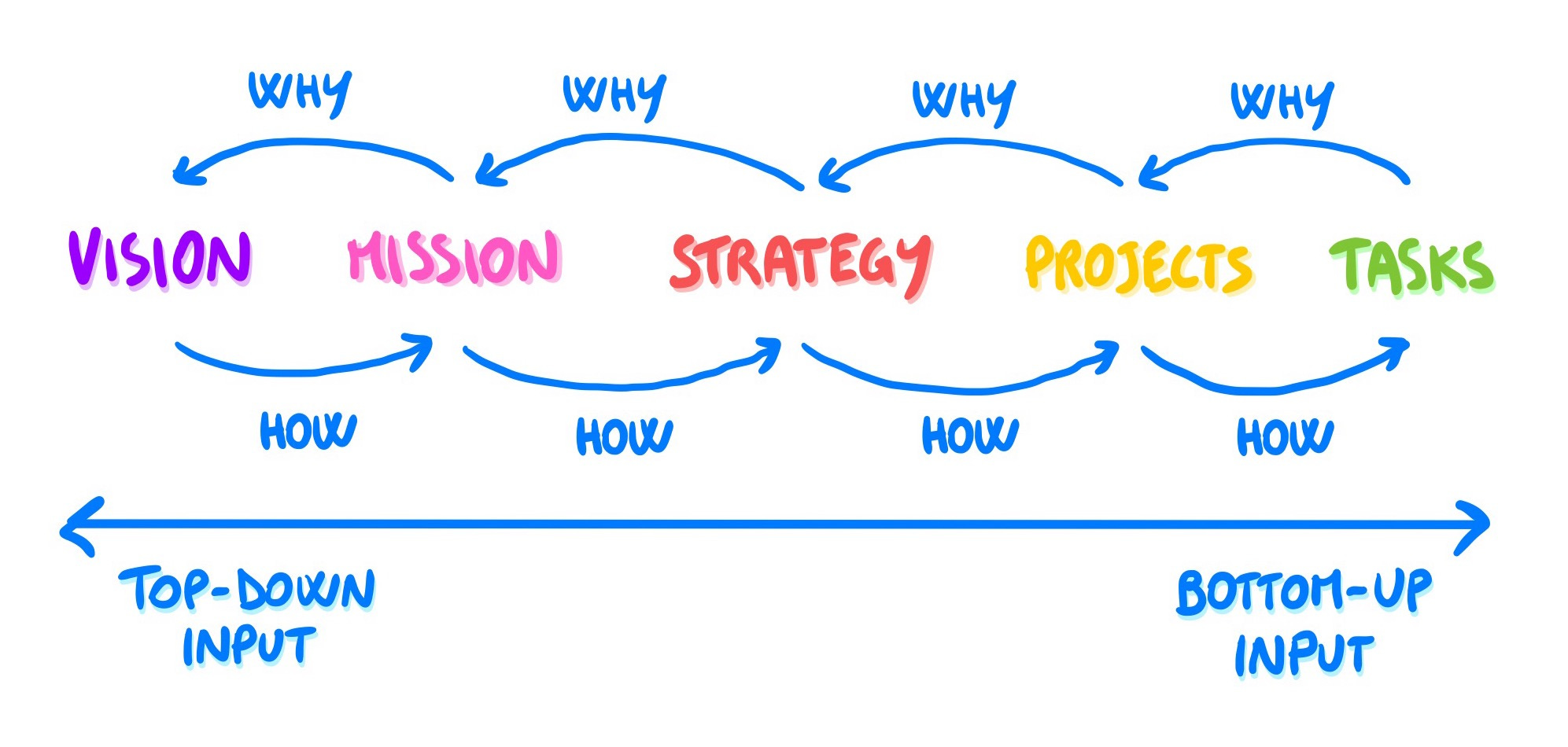
All these concepts are important because they represent how the torch of your mission gets passed down to the work of the individual teams and people. All the benefits we discussed, like purpose, alignment, and autonomy, are only possible if this link is clear, visible, and uninterrupted.
I wrote a full piece this summer about vision, mission, and breaking down work 👇
3) ❤️ Is scraping responsible?
Scraping has a somewhat shady reputation, but can you do it responsibly? The short answer is yes, but it's not straightforward.
This is still largely uncharted territory, so let's dive into both the current regulatory framework and my personal moral compass.
Regulatory framework 📜
The legal side is still murky and subject to interpretation, but here are some guidelines you can keep in mind:
😇 Fair and transformative use — in some jurisdictions, like the US, scraping may be protected under the fair use doctrine if 1) the use of the scraped data is sufficiently transformative (e.g., for research, commentary, or criticism) and 2) it doesn’t harm the original content owner’s market.
📝 Contractual obligations — many websites have Terms of Service that explicitly prohibit scraping. Violating these terms can lead to legal action for breach of contract. The problem is: it’s not always clear when websites can enforce these contracts, in fact… 👇
🌐 Public Webpages — some courts have ruled that scraping publicly accessible data (e.g., data not behind a login wall) does not constitute unauthorized access, and TOS can’t be enforced in that case because the user didn’t explicitly accept it (as they would if they had logged in).
It is also worth noting that bypassing CAPTCHAs and IP bans generally does not qualify as unauthorized access.
So where does this leave us?
Moral compass 🧭
I believe that whenever the legal framework is uncertain or contradictory, you can’t blindly rely on it and distance yourself from ethical considerations.
Of course, this is a personal stance. I have no pretense to say this should be universally valid, nor will I judge others (most of the times 🙃) for doing things differently.
When it comes to scraping, I ask myself two questions:
🏆 Does it bring any upside to the data owner?
🤝 Is it coherent with the intended usage of the data?
To move forward you need at least one strong yes.
The simple version is: if you are using data in a way that is wildly different from what was intended, it should cause no harm to the owner.
We published a full primer on web scraping a couple of months ago, and it was super successful 👇
And that’s it for today! If you are finding this newsletter valuable, consider doing any of these:
1) 🔒 Subscribe to the full version — if you aren’t already, consider becoming a paid subscriber. 1500+ engineers and managers have joined already! Learn more about the benefits of the paid plan here.
2) 🍻 Read with your friends — Refactoring lives thanks to word of mouth. Share the article with your with someone who would like it, and get a free membership through the new referral program.
I wish you a great week! ☀️
Luca