

Dunning-Kruger effect, good onboarding, and the Conway's law of microservices 💡
Monday 3-2-1 — Edition #46

Hey, Luca here! welcome to the Monday 3-2-1 ✨
Every Monday I will send you an email like this with 3 short ideas about engineering management, technical strategy, and good hiring.
You will also receive a new long-form article every Thursday, like the last one:
To receive all the full articles and support Refactoring, consider subscribing if you haven’t already!
p.s. you can learn more about the benefits of the paid plan here.

🐺 QA Wolf
Before we dive into this week’s ideas, I want to spend a few words to promote QA Wolf, whose team I got in touch with just recently.
In-house QA takes years to scale. QA Wolf takes weeks.

QA Wolf will build, run, and maintain your automated end-to-end test suite — and get you to 80% automated end-to-end test coverage in 4 months.
Your automated test suite runs entirely in parallel on QA Wolf's infrastructure so you get results in 5 minutes or less for fast, confident shipping.
From their website you can schedule a demo, get a 90-day pilot, and browse plenty of case studies from real-world companies 👇
Now back to this week’s ideas!
1) 🥷 The Dunning-Kruger Effect
The Dunning-Kruger effect is a well-known phenomenon in which experts in some domain are somewhat less confident that amateurs.
It isn’t always so, but it seems that, by drawing your skill progression on a time scale, there is a valley in which, although you have acquired decent expertise already, you can be more insecure than when you started.
Put it in another words, there is a significant period of time in which the more expert you become, the less confident you are.

How can this happen?
If your knowledge increases but your confidence decreases, it means that your expectations about what you should know are increasing faster than your knowledge itself.
This is possible, and even likely, because of how our learning works.
In fact, for any given subject, we can bucket knowable things into three categories:
🟢 Known knowns — our actual knowledge.
🟡 Known unknowns — things we don’t know and we are aware of it.
🔴 Unknown unknowns — things we don’t know that we don’t know.
We can only expect from ourselves things whose existence we are aware of, that is, (1) and (2). But when we are learning some domain, for a good while we may discover new unknowns faster than how we are able to turn them into knowns.
As long as this happens, our confidence goes backwards, while we see what we need to learn growing faster than our knowledge.
I wrote a full article about growing your confidence and dealing with impostor syndrome 👇

2) 🎒 The Three Levels of Onboarding
Onboarding is one of those overlooked processes that sometimes are expected to just happen.
I suspect this is because of a couple of reasons:
🧱 It feels like a commodity. Once you get past a baseline of quality — that is, here are some docs, here is your team, here is what you have to do — it doesn't seem there is much room for improvement.
📈 Performance is hard to measure — making it tough to assess how the process is actually doing. Which in turn makes it hard to improve.
To make onboarding better, I have two major pieces of advice:
🔨 Treat it as a project — projects have a goal, a beginning and an end. Onboarding should make no exception. Create a series of activities that, once completed, have covered the basics to allow new people make a positive contribution. Pretty much like the introductory chapter in a videogame.
3️⃣ Consider the three levels — technical, managerial, and cultural. Make sure you don't just cover the basic needs for the everyday job (technical), but clarify people's role within the company (managerial) and help them feel part of the team (cultural).
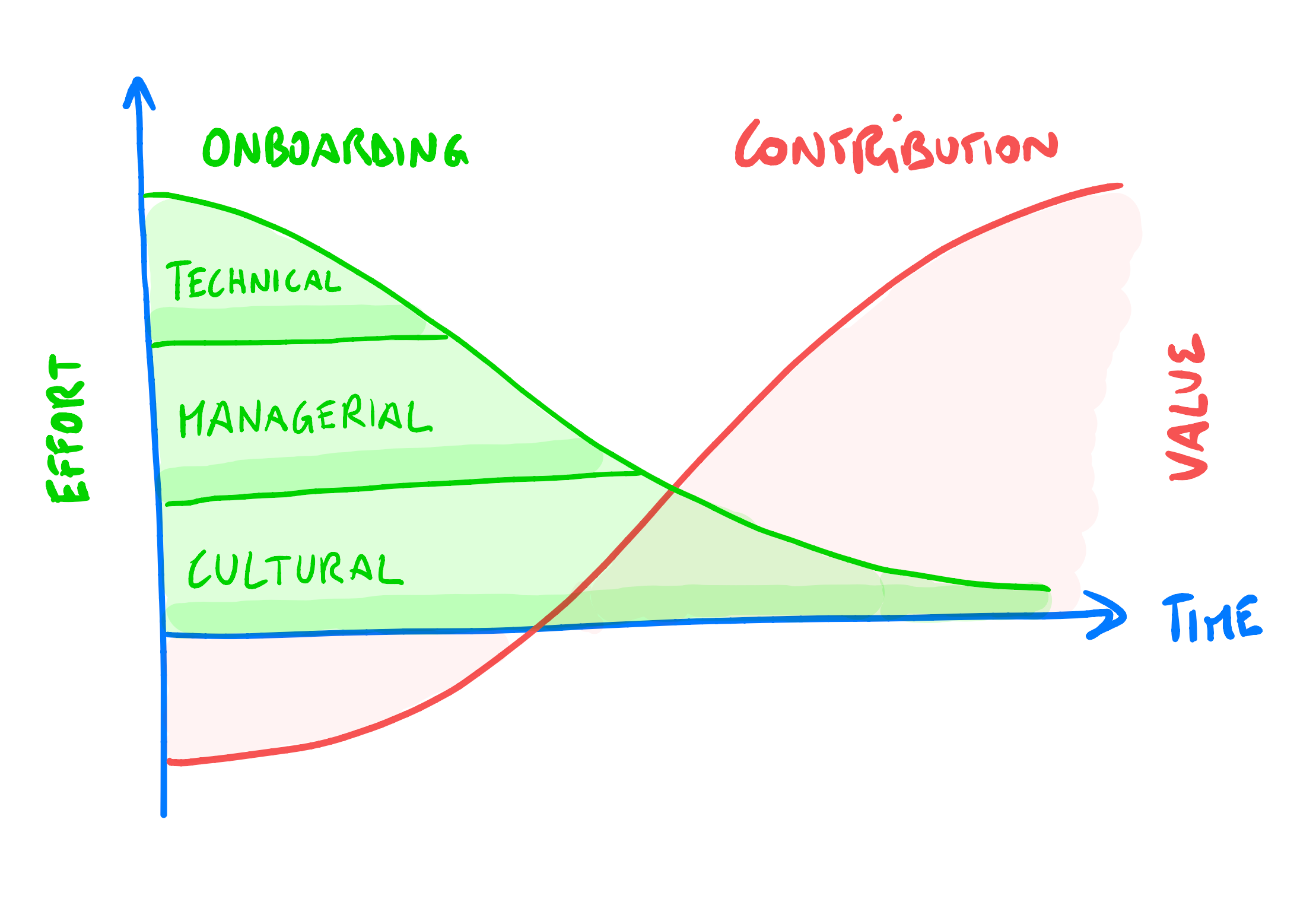
When you combine the two advices, you get that for each level you should create a series of activities to cross off, to consider onboarding complete.
You can find more advice about onboarding employees in this previous Refactoring article.
3) 🗿 Organizational benefits of microservices
I have come to believe that the benefits of microservices vs a monolith are mostly organizational, rather than technical.
This doesn’t make them less important, though.
As by Conway’s Law, your software design structure gets eventually shaped around your team’s communication structure.
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization's communication structure.
— Melvin E. Conway
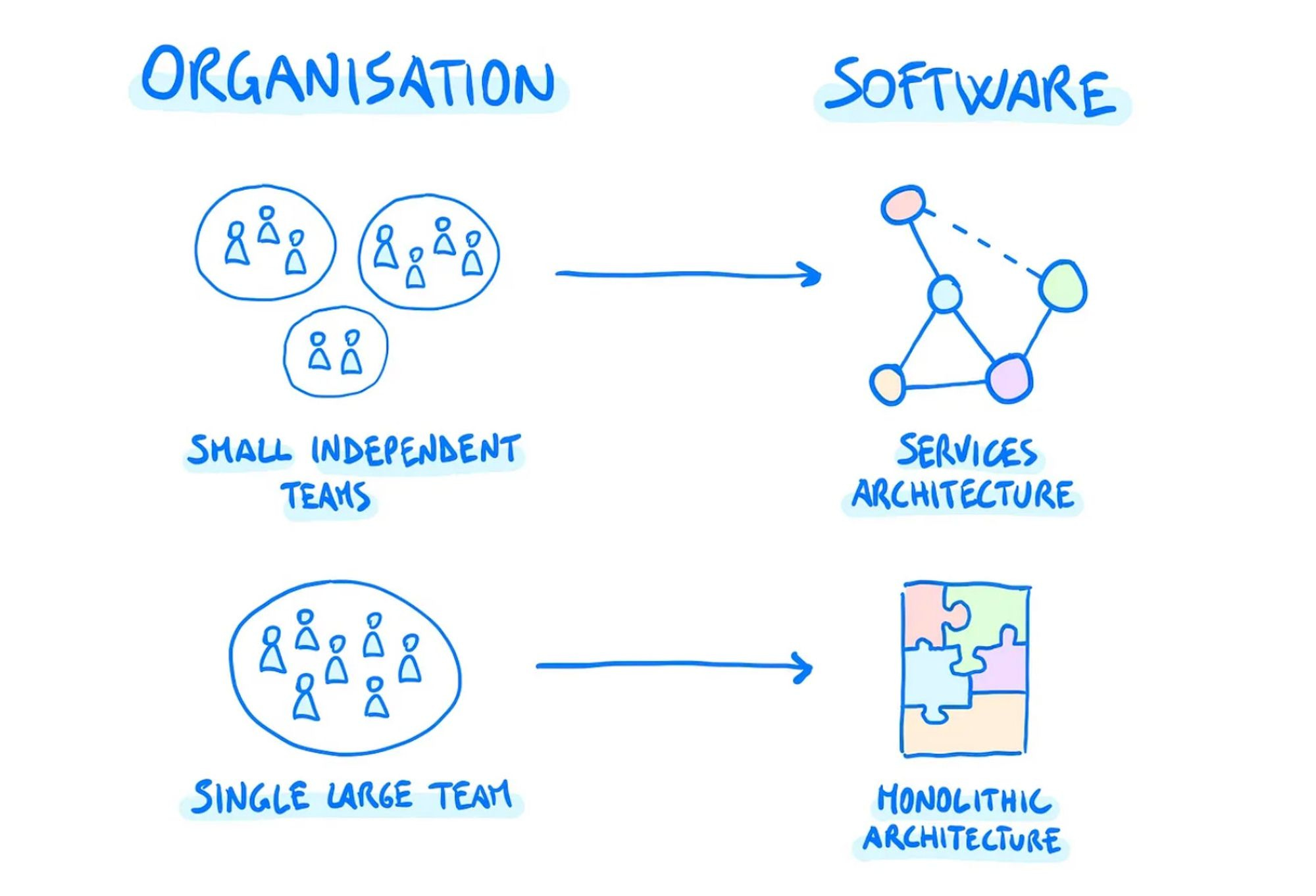
So, if your team is large and you want to organize it around small independent teams, you may need to gravitate towards a service-based architecture.
The opposite is also true: you won’t probably get the full benefits of microservices as long as your team stays a single large unit. The overhead will not be worth it if it is not matched by the communication benefits brought by autonomous teams.
It seems to me that a solid recipe for any team might be to focus on modularity, and spin off independent services whenever you want to enable independent workflows, rather than (supposed) stronger technical qualities.
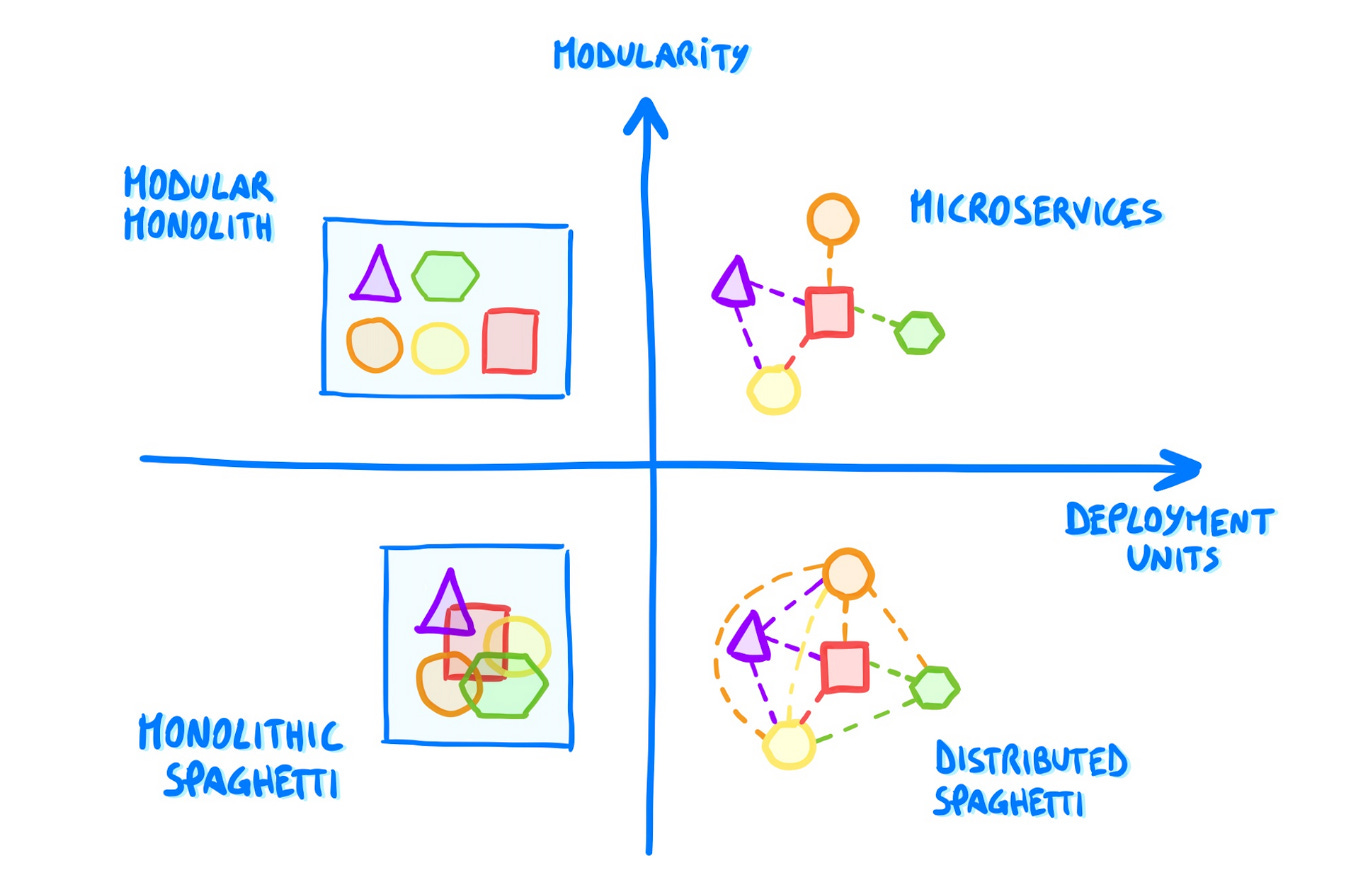
You can find more ideas about monoliths vs microservices in this recent Refactoring article:
💻 Typo
Last week we talked about Typo, which is a smart tool to help engineering teams code better, deploy faster, and stay aligned with their goals.
If you missed it, as a Refactoring reader, you can still get 30% off any Typo plan 👇
And that’s it for today! If you are finding this newsletter valuable, consider doing any of these:
1) ✉️ Subscribe to the newsletter — if you aren’t already, consider becoming a paid subscriber. You can learn more about the benefits of the paid plan here.
2) ❤️ Share it — Refactoring lives thanks to word of mouth. Share the article with your team or with someone to whom it might be useful!
I wish you a great week! ☀️
Luca
I revamped the onboarding process for an English blue light emergency service few years back. Main point I concluded was if you get this right both the employer and employee benefit over period they're together. Get it wrong and it's very difficult to come back from it for either. Private companies have greater flexibility in terms culture and money spend than public service,but that isn't an excuse to leave it merely as a tick box application process driven purely by cost and function.
There are a few things that are worth knowing about Dunning-Kruger: (a) the problem of "mount piety" and "expert beginner", and that some people are stuck with 1 year of experience 10 times https://theredqueen.substack.com/p/dunning-kruger-power-effect https://www.alchemists.io/articles/expert_beginner (b) "dilettante point" of cynical thought https://everythingstudies.com/2017/08/28/dangers-at-dilettante-point/
Questions: What are the train/transfer/re-tire procedures for each of the cases? What are some good indicators that said person is not fit for a career (e.g. Asian parental pressure)? What are the main difference between a cognitive/skill block and an affective/teamwork block?