


This edition is brought to you by ⛏️ Bright Data, the all-in-one platform to turn websites into structured data.

This video by Fireship ☝️ shows how they use Bright Data's Scraping Browser together with Playwright and ChatGPT to do some pretty advanced web scraping from Amazon. This process could easily be applied to a wide variety of AI web scraping projects.
The Scraping Browser includes powerful unlocking tools like proxy rotation and cooling, CAPTCHA solving, browser fingerprinting, automatic retries, and more — so you can easily get the data you need.
1) 🎈 Meeting buffers
If your agenda is packed with meetings, a simple trick to keep your sanity is to schedule them to be 25 or 50 mins long.
This way, you always have a buffer of 5 or 10 mins in between them to reset your head.
In my experience, it is also better to put this buffer at the beginning, rather than at the end. E.g. you schedule a meeting from 14:05 to 14:30, rather than 14:00 → 14:25. Somewhat, having the buffer at the beginning counters the inevitable few minutes of waiting for people to join, so it’s a win-win.
More ideas on defusing stress:

2) ✏️ Naming files and folders
Good names are important for making the various parts of the codebase discoverable — especially file names and folder structures.
There are two main ways you can find something in a codebase:
🔍 Direct search — you grep for a file/folder name, or part of a name.
🔀 Navigation — you navigate through the folder structure.
In almost any codebase, good structure for navigation matters more than individual file names. In fact, if you do well with the former, you get some leeway for screwing up the latter, while the opposite is not true.
So, as a rule of thumb, you want to encapsulate as little context as possible into file names. E.g. if you have a Hero component, you should probably call it Hero.js and put it into a components folder, rather than calling it HeroComponent.js and put it into the root.
This was a trivial example, but many similar cases are not. In general, be suspicious of two things:
Too much context going into file names.
Bland folder structure that does not tell you anything about the product.
About the latter, I am generally a fan of the Screaming Architecture approach by Robert Martin, which promotes creating structures that scream the domain they are about.
He compares software architecture to building architecture: when you look at the blueprints of a building, you should immediately understand what the building is about. If you see a kitchen, a living room, and a bedroom, you know you are looking at a residential building. And the same should go for software.
I have a caveat, though.
Martin appears to view the structures promoted by full-stack frameworks such as Rails or Spring as negative examples — because they are bland and do not scream anything about your app.
The way I see it, though, to stay within the building metaphor, is that frameworks like Rails are ways to create blueprints for different types of buildings.
So, it’s like Rails is for building residential homes, and it already gives you a folder structure with a Kitchen, Bathrooms, Dining room, etc.
This is undeniably good, because:
Everybody knowing the framework knows where to look at in any project.
It teaches everyone the basics of what residential homes should look like.
Of course, this means the framework is opinionated and you may not agree with it, but when you do, instead, it saves you a ton of cognitive effort. Then, there is still room for a screaming architecture, inside the business logic folders.
You can find extensive advice on naming things in this Refactoring piece:
3) 🤖 Retrieval-Augmented Generation
When you look at how companies are using LLMs, either internally or inside their products, many use cases are about combining the capabilities of the base model with some company data. Think of AI chatbots, or summarization scenarios.
Many of these use cases are implemented through Retrieval-Augmented Generation. As opposed to prompt engineering, RAG is an actual architecture: it adds an information retrieval component that allows to incorporate relevant documents from external sources, such as databases, document repositories, APIs, and more.
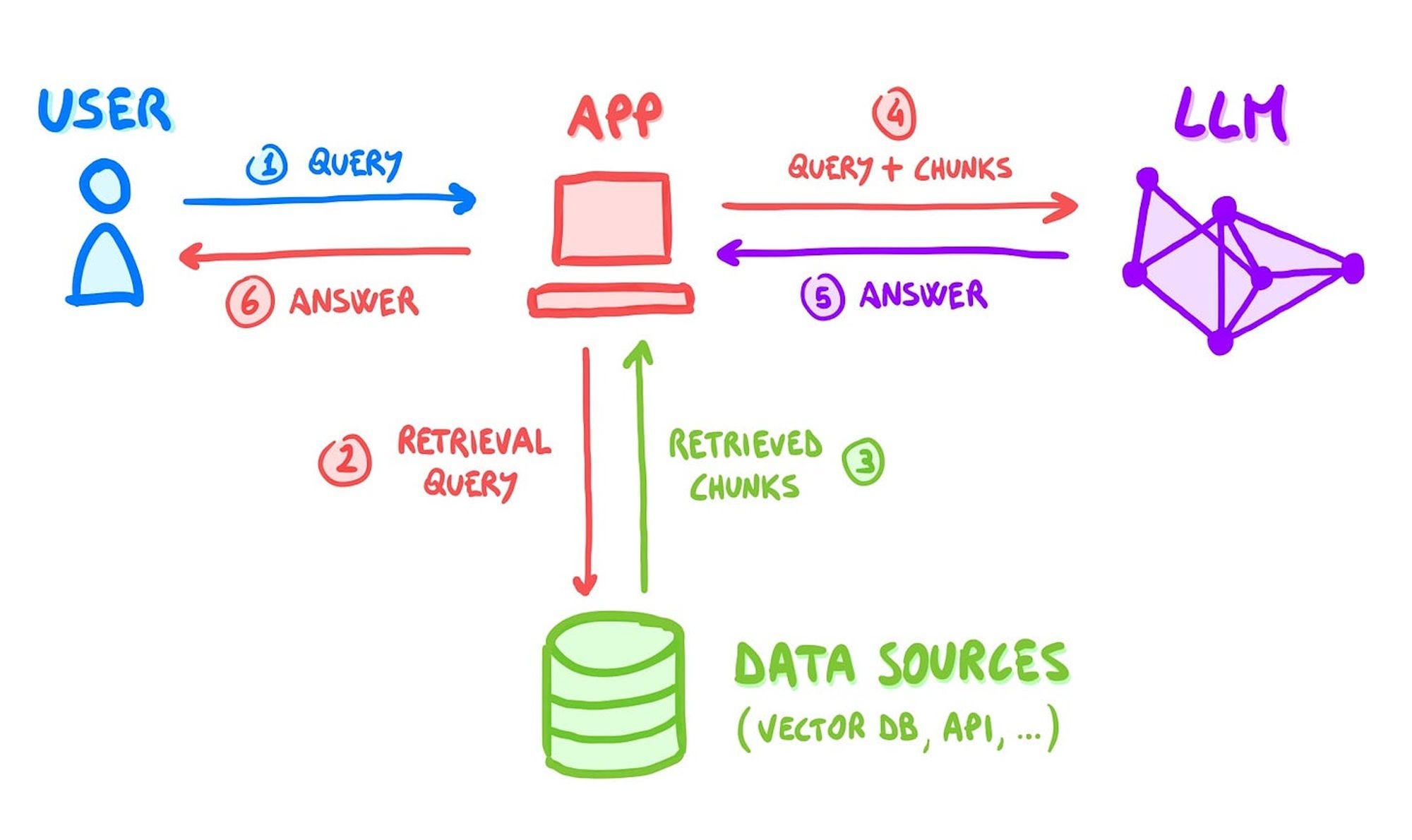
How it works
After the user submits a query, a first step of information retrieval is performed, where a separate system (not the LLM) extracts chunks of content that are relevant to the query.
Such content is added to the prompt as additional context for the LLM to be used:
RAG vs Fine-tuning
RAG use cases have some overlap with fine-tuning: in both scenarios you have additional data that you want to use and that does not fit into a prompt.
So when to use one vs the other? Basically, RAG is about queries that can be answered by using, each time, only a subset of relevant docs. Conversely, fine-tuning is about training the model with additional data to teach it how the world works, rather than copying from examples. It’s more show, don’t tell.
In practice, for example, if you had to build a chatbot for your docs workspace, you would probably do it with a RAG system. Each query would surface the most relevant chunks of content first, and the LLM would compose an answer based on them.
On the contrary, if you had to use an LLM for creating medical diagnoses, retrieving chunks of past medical records with a RAG system probably wouldn’t be enough. You should rather fine-tune the base model on the whole dataset of records.
Whenever both solutions work, however, RAG has strong benefits:
Cheap — it is extremely cheaper than fine-tuning
Easy to update — because data lives on external systems.
How to build a RAG system?
You can find plenty of tutorials online and going deep into this is out of the scope of this article. However, here is the tl;dr version:
🔨 Build it yourself — to make it in house, you should create an embedding of your data (e.g. via LangChain) and host it in a vector database (e.g. Pinecone or Weaviate). Later, you can easily query such a database to retrieve chunks of content and pass them as additional context to your LLM’s prompt.
🔌 Low-code-it — some low-code tools, like n8n, allow to create full workflows which include vector databases, querying LLMs, and processing data via LangChain. This looks very promising and by the time you are reading this I am doing various experiments with this.
💳 Use ready-made tools — for specific use cases, like chatbots, there exist tools where you just upload your content and they take care of the rest. Chatbase and CustomGPT are among the most popular.
You can find more ideas on how to integrate LLMs into your products in this recent Refactoring edition 👇
🗳️ The State of Engineering Productivity
Finally, I have a quick ask! 🙏 I am conducting a survey about what makes engineering teams productive: practices, usage of metrics, tools, etc.
If you want to help me out on this, you can fill out the survey below 👇 it takes less than 5 mins.
Thank you, it means a lot!
And that’s it for today! If you are finding this newsletter valuable, consider doing any of these:
1) ✉️ Subscribe to the newsletter — if you aren’t already, consider becoming a paid subscriber. 1500+ engineers and managers have joined already! Learn more about the benefits of the paid plan here.
2) 🍻 Read with your friends — Refactoring lives thanks to word of mouth. Share the article with your with someone who would like it, and get a free membership through the new referral program.
I wish you a great week! ☀️
Luca