

How to Prioritize Tech Debt 🔬
A data-driven framework that takes into account code health, frequency of change, and knowledge distribution.

I have always maintained lists of the things that get recommended in the Refactoring community: books, tools, movies, hobbies, software practices.
I started this as a way to keep the pulse of useful stuff in tech, but it has proved interesting for life in general. E.g. in movies, Interstellar got the undisputed top spot, ahead of the Matrix trilogy, while in hobbies, cooking (surprisingly?) beats videogames.
In these special rankings, there is only one person that appears twice, in different categories: Adam Tornhill. Adam is, at once, the author of Your Code as a Crime Scene — one of the most recommended engineering books—and the founder of CodeScene — one of the most recommended tools.
As you can tell by the names, the two are related. In fact, CodeScene provides a simple way to implement the ideas exposed in Your Code as a Crime Scene: the former was born out of the success of the latter.
But what ideas?
Adam developed, over time, a thoroughly original take on one of engineering’s eternal struggles: managing technical debt. Or, in his own words, on maximizing long-term productivity by working on the right stuff.
I talked with Adam several times recently, and today I will cover some of the best ideas I learned from him, which you can apply in your daily work.
Here is the agenda:
🔪 The Crime Scene — what forensic psychology can teach us about software.
🔄 Frequency of change — problematic code == complex code that is changed often.
🚥 Code health — the hard numbers about how bad code sinks your ship.
🏛️ Knowledge distribution — the surprising reality about your top performers.
📈 How to improve — designing strategies to improve productivity through code quality.
Let’s dive in!

Disclaimer: I am a fan of what Adam is building at CodeScene and I am grateful to him for partnering on this piece!
We will also be running a webinar together on Sep 17th about these same topics, which you can check out if you want! You can also try CodeScene for free below 👇
🔪 The Crime Scene Metaphor
Adam has a peculiar double degree in Psychology and Engineering, which has shaped many of his ideas about code quality and developers’ behavior.
Being passionate about forensic psychology, he compares the state of a codebase to that of a crime scene: we shouldn’t only look at the current state, but also ask ourselves what happened and why.
In that respect, static analysis is useful but limited, because it takes into account only the latest version of the code. So, the core idea behind Adam’s work is to combine that with a thorough analysis of version control history, to uncover trends and understand how team members interact with the code.
But how is that useful? Let’s explore the three key dimensions that you should measure, taking advantage of this approach: code health, change frequency, and knowledge distribution.
🔄 Change frequency
There is no 100% consensus on the definition of technical debt, but most versions point to bad/complex code that has become hard to change.
When you think about it, though, this is only a problem if you actually need to change that code. Bad code that is stable doesn’t pose any concern by itself.
So, your tech debt work should be focused on what Adam calls hotspots: the parts of your codebase that are, at once, 1) problematic for their structure, and 2) frequently subject to change.
While this seems obvious in retrospect, as humans we are not good at intuitively judging this. As a consequence, most real-world work on tech debt is misguided: it often happens either on bad—but stable—code, or on areas that are active but already in relatively good shape.
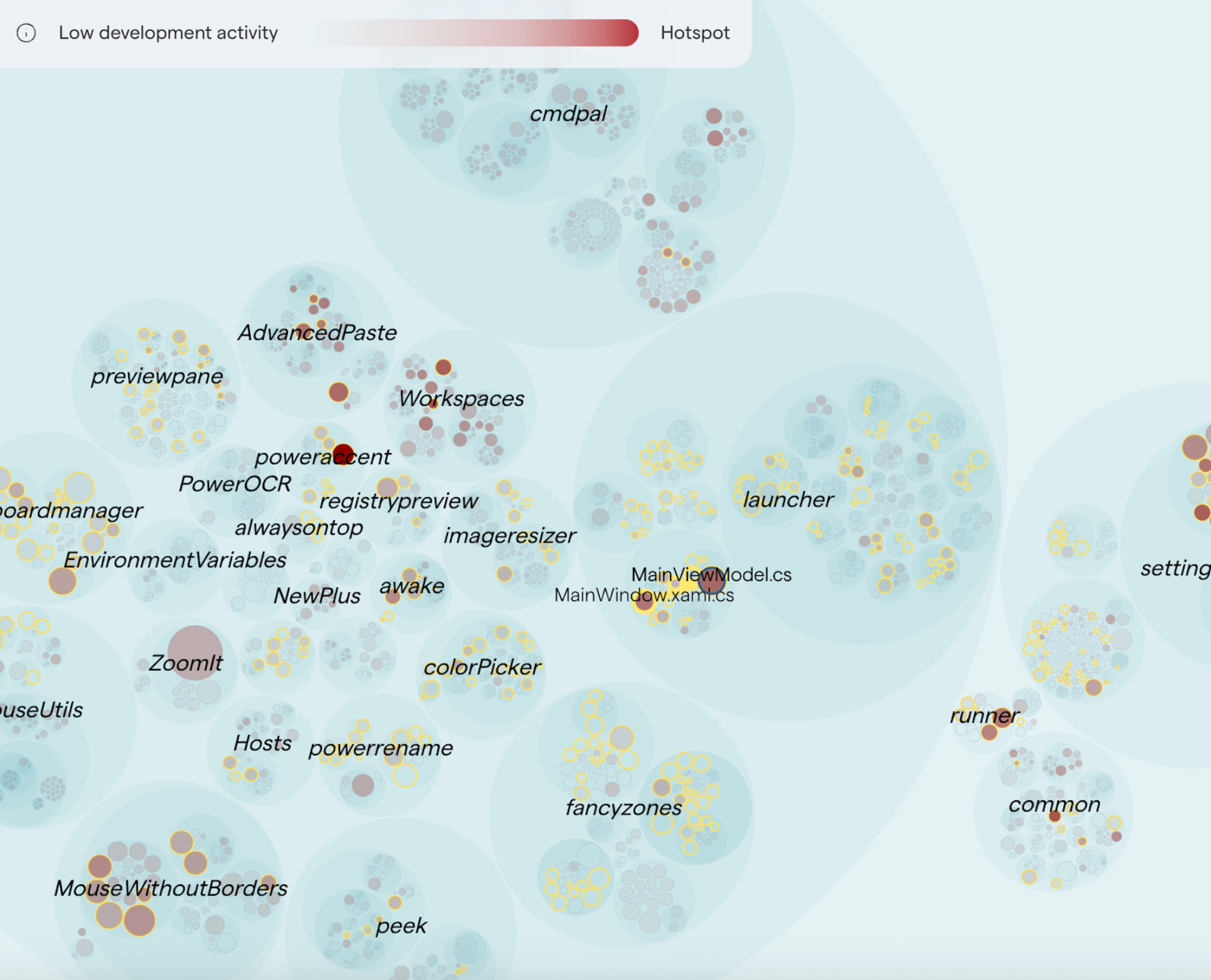
Part of what makes this hard to evaluate is that the activity distribution is extremely skewed: in your average codebase, you can usually find around ~5% of the code that gets 90% of the activity.
This hit home for me, as it made me remember something that happened several years ago.
During my time as co-founder of my startup, we once had a promising M&A conversation with a partner. Talks were in an advanced stage, and the buyer brought in a consulting firm to perform technical due diligence on our product.
They did various static analysis runs and they found—as we expected—several areas of poor quality code. We knew that because over time, as it is often the case for startups, we doubled down on some specific parts of the product—the ones we cared about keeping healthy and clean—while gradually phasing out others. On the latter, code had often stayed in an experimental stage: less testing, more duplication, etc.
What I didn’t expect, though, is that this proved hard to argue. We pointed to the core, strategic parts we were proud of, while the firm pointed to a bunch of sketchy stuff that was marginal for us, but equally part of the whole for them.
In other words, the frequency of change was not taken into account.
Eventually the M&A failed for a variety of reasons, and while this was not explicitly mentioned as a blocker, I always suspected it contributed to the outcome.
🚥 Code health
So, if hotspots are defined as 1) complex code that 2) changes often, so far we have mostly talked about the change often part — which is the easiest to figure out.
If you ever happened to try any code quality tools out there, you will probably know that there is little consensus around what “complex” or “bad quality” code means. Even more so, it is hard to link poor quality to actual bad outcomes for your team.
So, Adam set out to fix this and did two things:
Developed his own algorithm to assess code health, which considers 20+ factors and heuristics.
Investigated and eventually published peer-reviewed research to prove the connection between bad code and bad outcomes.
He found that bad code consistently leads to three sets of issues: number of defects, development time, and uncertainty:
🐛 Defects — low quality code contains 15 times more defects than high quality code.
⏱️ Development time — resolving issues in low quality code takes on average 124% more time in development.
⁉️ Uncertainty — issue resolutions in low quality code involve higher uncertainty manifested as 9 times longer maximum cycle times.
The third item is what strikes me the most: it doesn’t just take more time to do stuff on bad code — it’s also very hard to estimate how long this time will be. I think this will match everyone’s experience, yet it is nice to see it backed by numbers.
🏛️ Knowledge distribution
Version control is not only useful for understanding how and how often code has changed over time: it also allows us to study authorship.
What can we discover by looking at who makes changes to what code?